
Approaching Networking
Stephen Beaulieu
|
March '98 Be Developers' Conference Approaching Networking Stephen Beaulieu |

Stephen Beaulieu: I'm going to go ahead and get started here. I'd like to welcome you to Approaching Networking. My name is Stephen Beaulieu. I'm one of the developer technical support engineers at Be and the one who all your networking bugs and the like will go to.
Before I get started a couple things: One, I'm not going to take questions while I go through this. I have a lot of information to go through. We're going to have time for Q & A at the end, if I'm not interrupted.
Also, for those of you who have been to these conferences before, you might be aware that the person in charge of networking and, in fact, our one and only networking engineer was Brad Taylor, an excellent engineer. He has moved on in the last couple months to some other startup opportunities and we have a new networking team that has come in over the past five or six months.
I want to introduce you to them, just because they're going to help fend off some of the questions at the end.
So starting off we have Russ McMahon, who's the lead of the networking team.
(Clapping.)
Stephen Beaulieu: Michael Alyn Miller, who's one of the engineers.
(Clapping.)
Stephen Beaulieu: And our veteran of the team right now, Igor. I actually don't now how to pronounce your last name.
Okay. Going to do things a little bit differently than might have been done in the past Approaching Networking sessions. I'm going to cover a series of things.

Be was born of the web, you'll hear in some of our marketing things. Most of people who are -- who are working with the BeOS in terms of user and developers in the past, they have Net connections, that's kind of how we do business. Therefore, having your applications be Net aware is very important and there's several different -- different layers of doing that and we're going to go through the different methods.
We're going to talk a little about using Internet applications, like an E-mail client and a web browser and communicating with them through your application and using their facilities to basically make you better aware.
We're going to talk about using the Mail Kit for sending mail, and then finally we're going to go into using the Network Kit and talk about sockets, how we're the same and how we're different from say BSD and say WinSock and kind of some code samples of how to use things.

So we're going to go ahead and start off on using Internet applications. This is fairly straightforward. Pretty much everything will be shown on this slide.
The idea is you've got an About box or you have a url on your About box and you have a support address and you want people to be able to click on that address and go ahead and make a Net connection.
Well, the idea here is to leverage off of applications that already know how to do this, and after you go ahead and figure out exactly what they have clicked on in your view, which interfaces you, go ahead and let's deal with just an HTML link for example.
We have a sample here where we have the link that we want to go to, which is just the developer section for the Be web site. Then we use our BApplications global be_roster to go ahead and launch the preferred application that knows how to handle text/html, which in most cases is going to be NetPositive on most people's machines. And we pass it a command line argument the link we want to go to, that will currently, if you're going in NetPositive, it will go ahead and bring up NetPositive and bring up the site. That's a very easy way to make your application pretty much Internet aware. It looks like you've done a lot of work in the background, but you really haven't.

Same thing with an E-mail client. You go ahead and have a mailto address and you launch the preferred application for dealing with text/x-email, pass it to it, it will go ahead and do the same thing.
Now, there are some things we want to make better here and I've been talking a little bit with the Net Team and from ideas from a developer Round Table that was around last night, one of the things I'm going to be proposing in the near future is identifying new MIME types to handle not file types, but to handle sort of message types.
So, for example, what would you do if you wanted to have download my documentation from somewhere in FTP? Currently in applications like BeMail when you go ahead and do that it goes to NetPositive, because we know that NetPositive knows how to handle that, but there's no actual file type, for example, for identifying FTP.
So hopefully what we'll be doing is making some suggestions and adding them to applications that are currently available for preferred types for, say, an actual HTTP connection, an actual E-mail connection, much like we're doing here, an FTP connection, things that aren't necessarily identified by the type of file you're going to get, but by the transport mechanism you're going to do that. And then people who write Internet applications, you folks, if you want to do that, can register those as types, you can get set up as preferred types and the right thing will happen. If you want to use Kftp or if you want to use NetPositive for handling FTP connections, the right thing will happen.
That's it. That's pretty much it for the first half. If you do these sorts of thing you can get just a lot of Internet awareness inside your application, make it look like you've gone to the effort of keeping yourself connected.
Next thing I'm going to move on to is a little bit deeper, if you want to get a little bit more involved. We're going to talk about the Mail Kit.

Now, the Mail kit is a series of APIs for sending and receiving mail using the built-in mail_daemon These calls will not work if you, say, loaded up Adam and are using their mail_daemon, which is another reason we want to try to find some other ways of identifying things.
And I'm not going to talk about checking mail. There are some improvements we want to make to checking mail and it's generally not the sort of thing that unless you're writing a mail client you particularly need to worry about, but a lot of applications might be worried about sending mail. So that's what I'm going to do. I'll start off briefly talking about the basic structure of E-mail, of the BMailMessage class and a little bit of sample code for using that class.

Hopefully, all of you have seen E-mail before and you're aware that it pretty much consists of a series of headers like who the message is to, who it's from, what the subject line is, if anyone's been carbon copied or blind carbon copied or the like. It has generally some form of content which tends to be a text message and then it may or may not have additional enclosures added to it.
Well, that makes sense, it's an intelligent way to go about doing things and oddly enough, when we created the BMailMessage class that's how we went about doing things. It's a class only to handle the sending of mail. If you want to read a mail file you have to create a BFile and go look through all its attributes on your lonesome. We don't have a wrapper class that just gives you the information from the E-mail file.
But for sending it's fairly straightforward. There's a series of calls to basically specify the content of the message, including adding a header field, adding content and adding enclosures and then, of course, the ability to send a message.

Now, when you send a given message there are two parameters that are interesting. One is the send_now which defaults to false and if you leave it at false just the next time that the mail_daemon is going to check mail it will go ahead and send anything that's queued up at that point in time, but you can tell it to go ahead and send something immediately.
And the other parameter is remove_file_after_sending. Basically the way the BMailMessage class works is when you actually create the mail message it's saved onto disk as an actual mail file with some flags set basically saying send this at some point in time in the future, and that's how you keep track of mail that has already been sent.
So the default would be to go ahead and save that to a file and send it, but you can basically leave no trace of the mail having been sent.
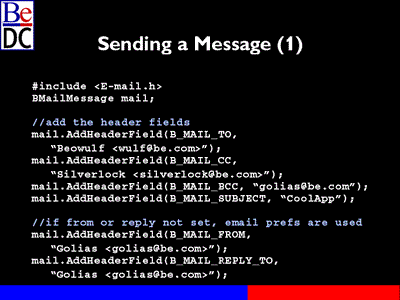
So little bit of sample code for sending a message. All of the information about the BMailMessage class is held in the header file, <E-mail.h.> But we're going to go ahead -- that defines the class, it also defines a series of constants for identifying basically the different headers that you'll want to go ahead and add to it.
So we're going to go ahead and create a BMailMessage on the stack, we'll go ahead and add a series of header fields. So we'll start off by who we're sending the mail to, which will use the BMail to constant and we're passing to Beowulf@be.com. Then we can add the CC header file, go ahead and add the, you know, just BCC's, just a series of the different headers that you want to add to it, including down to the subject.
This -- when -- if you don't specify who the mail is from or who the reply-to header should be set to, it will use the E-mail preferences, basically the POP account, the internal POP account that's been set by the E-mail preferences applications. You can override that by actually adding those headers and it will respect what you've added inside the message, which can be handy. So we've gone ahead and we've basically said from golias@be.com.

Sending the message on the next page. We'll go ahead and we'll just create a content, just a basic string. We'll add that content, then we'll add actual enclosure for the file and we'll send it. It's that easy. What this has done is this has created a message to wulf@be.com that's been cc'd to silverlock and it's been blind carbon copied to golias, the sender of the mail. The from and reply to have been sent. The content is 'Here's my cool new application', the subject was 'CoolApp', and it includes the enclosure file.
That's it. Completely comprised and if the message_daemon is up and running, it will send this. If the message_daemon isn't up and running the Send() call will return an error and then you can go through launching it by the Roster. There's some strange things with that that you might want to look into.
Again, this will only work for the built-in mail_daemon, but you can use this interface to, for example, throw up your own dialogue so you can have a support address. You can go ahead and click on that support address and it will fill in a bunch of information and it will just give you a form that the people can fill in to put the information in and you can send it out to the Net.
Or if you want to send a set message, like subscribe me to your mailing list, they could click on that and in the background it would send the appropriate message, it would grab the information from the E-mail preferences so you know who was being added and do it automatically, nothing else, a one-click operation.
And I've seen a couple people raise their hands. I'm going to take questions at the end because I have a lot of material to go over and I want to make sure people are available to go to the next session.
That's it for the Mail Kit. Those are the two upper-level ways of dealing with the Internet and we like this sort of design philosophy whereby people can easily access the Net without having to do the hard-core programming. And if we were to add extensions to the API it's likely it's going to be more along those lines, because the socket stuff is underneath.
And it will be possible, of course, for other people to write shared libraries that do the underneath that basically abstract these sorts of things for, say, an FTP transfer or something like that. We would encourage people to work on solutions that do that to make it much easier for people who are writing a word processing application to, you know, grab new add-ons, things like that, without any other user intervention.

So the rest of the session I'm going to be dealing with using the Networking Kit. We had a BSD-like socket interface and there are things that work the same, things that don't work the same as BSD, and I'll go through some of that in a moment.

So I want to cover the actual socket interface and what it means and how it's different, going to look at the header files, netdb.h and socket.h, that handle the DNS functions and the actual socket manipulation functions, and I'm going to have some sample code again that will quickly build a client and a server and then some samples for sending and receiving information.

So go ahead and talk about the socket interface. Much like WinSock, we are BSD-like. Most of the API systems with the Net nowadays, with the exception of perhaps Open Transport on the MacOS, which is streams-based, is basically some derivative of BSD sockets, the same sort of function calls and I'll go over those.
How does this differ from WinSock? First, how many of you have actually programmed BSD sockets before?
Okay. A lot of this stuff is going to seem very, very familiar to you. For those of you haven't, how many of you have programmed with WinSock? And how many of you have actually done BeOS programming in the network again? Far fewer. That's good.
The main difference, take WinSock because that's the first sort of thing. The main thing particular about WinSock that we don't do is we don't have any of the WSA function calls. Those were around from the days when windows was a single-threaded system, and you could not block when you were trying to send of receive something, because nothing else would happen anyway. So set up a messaging-based system to basically handle that in the background as available and you could go on doing your things and the system wouldn't get locked up.
We're a multithreaded system, we don't have to worry about that. We do a plain Jane style BSD socket interface, so you won't see WSA socket calls. If you're wanting to port some of your Windows code you'll need to change those and there will be some things you need to worry about. And if you have questions specifically about that, the best thing to do is go ahead and E-mail devsupport and I'll get the message and I'll work with you on those. Versus BSD, and a lot of these might carry over from WinSock, I'm not that familiar with, but same sort of issues.
The difference is in our networking from BSD: sockets are not filedescriptors. You can't use the normal file system calls to handle that. Sockets are also not inherited over fork(). Our DNS functions are thread-safe, unlike BSD, and we have far fewer, currently, socket options, options you can put on the socket, like making it blocking or nonblocking or whether you want to use the socket for various connections.
What this means is that basic BSD Unix server and client code, go grab Apache for example, and wanted to port it over to BeOS, it's not going to be easy, because all of those servers depend upon forking, they depend upon sockets being filedescriptors, they depend upon forking and you can get all the sockets and everything on the other side, so you can continue that.
We don't support that. It's not as efficient to do with our system. We have a much lighter weight threading model, for example, so it's a lot easier to handle -- when you do a call to fork it basically creates a duplicate copy of your application that runs through the rest of the code. That takes a while to go ahead and it's very resource-intensive to do that. There's no need to do that with our threading model.
So I'm going to go ahead and get into some implementation suggestions, how we advise that you handle some of these differences.

What we found the best performance for is to use one thread per socket. That's what we used inside the Net server. When you go ahead and create a socket, there is a thread that's spawned inside the Net server that handles grabbing the buffers and holds on to that. What we then suggest on the user side is that you also spawn a thread for your socket to read and write. That way that can safely block, if you need it to, while it's waiting for something, without affecting the main set of your code.
We suggest that you use kernel threads and that you don't use BLoopers, for several reasons. One, a BLooper, if you've gone through these things, does have its own thread, but the purpose of that thread is to run the message queue. It's not a thread that you want to set a block or something, those messages could pile up.
You could use a BLooper and then spawn an additional thread to actually handle all your socket stuff. That might work, because then you could have access to package information in BMessage using BLooper to send it off somewhere and handling things coming in. That might not be a bad idea, but even if you do that you do not want to make most of our socket calls from within a BLooper. And this is something to work on fixing, it's a bug we just recently discovered.
Because our DNS functions are thread-safe it means that we store -- when you go ahead and lookup, a domain-name lookup, we store a bunch of private data inside the kernel thread that you're dealing with. When a BLooper quits, it doesn't properly clean up that information, which means you can get something along the order of a 32K memory leak when you basically use a BLooper and add that, take it off.
We're working on fixing that. It's just a peculiarity of how BLooper needs to exit and us not having the code correctly. That's something we're working on. Don't know when that will be done, but for the time being for that reason alone you'll get a big memory leak if you use BLoopers, but the other thing is you just don't want to tie up the message loop trying to do socket stuff.
One last thing is that select as it's currently implemented is very inefficient. Lot of people use select to have one thread taking care of a series of sockets and they will get notified from select that this socket's ready for reading or that socket's ready for writing. Then they can have that one thread manage the different buffers and read and write.
The reason we suggest you use one thread per socket is if you use select we will, inside the Net server, spawn another thread for exactly that purpose of notifying you when it's ready to read and write and that thread, that's all it will do and if you handle it yourself for that one thread you can use that thread for other things for other times.
That again is an effect of the current implementation. I'm sure it's something that you can bug our wonderful networking engineers about to get fixed sometime in the future; when it happens they'll have to discuss. We're aware of it, but we have other work-around solutions.

So let's go straight from there into the headers, the sort of functions that are available, then I'm going to cruise these kind of quickly. If I'm going too fast for you, tell me to slow down. I won't stop to answer questions, but you can tell me to slow down.

The first thing we're going to be looking at is netdb.h. This handles basic DNS name service functions, identifying a port, a socket somewhere out there you want to connect to www.be.com. What are the internal mechanisms for identifying what actual machine that is and what port you're supposed to hook up to and the like? That's all under the domain of netdb.h.
One of the main structures you'll be playing with is the hostent struct and this is basically a structure that identifies either a local or remote host and it's got a series of -- series of members. It has an official name of the host, it's got a list of the aliases, it's got an address type, which is always in the BeOS AF_INET. I forgot the "I" over there, basically identifies as an Internet address. The length of what the address is in the long in here, which is always going to be 4 and then basically an alternative list of the actual addresses you want that are associated with it.
And this structure is used and returned by all of your DNS functions. So you've got a series of them. One is gethostbyname(), where you pass it a name that represents the, you know, the dot terminated, www.be.com.
We have another one that is called gethostbyaddress(), where you actually pass it -- you would want to get a host structure for some address long and if you cast it as a character. This is not the function you use to get, you know, an IP number string. You don't pass an IP number string in here and expect to get anything back. That's what the next two functions are for, inet_addr() and inet_ntoa(). They will convert to and from an IP string and the actual numeric representation of that and it's that numeric representation that you need to pass to gethostbyaddress().
So this is pretty much it for the netdb.h functions. That's what you need to identify hosts that you want to connect to.

They do have some generic byte swapping functions. One thing about Internet address is especially when identifying ports on a given computer and also in identifying an actual address is the network is big-endian. That's just the way the Internet works. Which means that if you want to connect things correctly you want to make sure you swap your multibyte data that will be used to identify where you're going to be connecting and you want to make sure that it is in the basically Internet order.
So we've got four different functions, two that will convert shorts from network order to host-order and two that will convert from host-order to the basically other way around. And these are actually just wrappers for the byte swapping macros that you might have stumbled across in one of my earlier sessions.

So now you can go ahead and identify where you want to connect to, how you're actually going to connect to it. That's done with the socket manipulation functions in socket.h. I've got sample code that actually shows you how to use all of this.
This is basically a definition of the sockaddr_in structure, which is what identifies a remote socket, basically an address you want to connect to. And it is made up by a family which describes what type of connection it is, an Internet connection and the like, and nine times out of ten you're going to be using AF_INET for that.
The port number that you're connecting to on that -- on -- on the machine and then finally, a structure which ends up just being a wrapper for another integer that actually identifies -- it's the long that identifies what the network number of the machine that you're connecting to.
Then there's some padding that you always need to go ahead and zero out and that's basically because on different systems the sockaddr_in may or may not be using the same sized bytes, so you have extra padding that you have to fill out in the end. So that's actually some of the basic functions for creating, closing and binding a socket.

If you want to create a new socket -- and a socket is basically a local token. It's an identifier on your system for a resource that can be used to connect to the Internet -- you go ahead and use the socket() function, you pass it a family, which again nine times out of ten is going to be AF_INET. You pass it a type, which basically describes what protocol, how you're going to be connecting. You pass it a protocol.
Type is either going to be essentially UDP or TCP. Let me briefly talk about the differences between them. UDP -- start with TCP, which is what the rest of the talk is going to be about. It's a transmission control protocol. It's a connection-based protocol for talking between two computers, which is basically I create a connection from me to the other computer and that connection stays open until I close it and across that connection I send requests and read and write.
UDP is a datagram-based protocol which basically means you don't have connections, connectionless, where I'm here and I know a machine's out there so I'm just going to send it a packet and that's it. There's no actual connection, there's no back and forth. I send stuff to it, it sends stuff to me. There's no guarantee, unlike in TCP, that it's actually going to reach there.
TCP underneath will go ahead and send and if it doesn't get acknowledgement of it will take care of making sure it gets sent, gets there and basically making sure the connection is done. UDPs you have no guarantees of being connected on the other side.
Why would you use one as opposed to the other? With most of the applications you guys are going to be writing TCP is usually the way you want to go, because you don't want to handle the overhead.
What do you use UDP for? It's used a lot in games. There's a lot more overhead in TCP. It handles more things. If you're running a game and generally a lot of times you'll be running a game on a highbandwidth network, and if you're not likely to be dropping a lot of packets there's a lot less overhead just sending them out in pipe and on occasion if they don't get to the other side sometimes it just doesn't matter if that actual frame doesn't show up there. It's not going to be that big of a deal. And if you do want to send it, it's so rare that something actually doesn't get acknowledged, that you can just go ahead and send it again yourself. But for most Internet applications TCP is the way to go.
So basically, again, back to socket(). You identify the family, you identify the type and most of the time the protocol that you're going to send you'll just use a 0 for it, because you'll identify that either a stream-based or a datagram-based type of connection and then if you pass a 0 it will just use the natural protocol for those types.
What socket() returns is a -- is a token. It returns an integer that represents that resource on your system. Any time socket() correctly comes back and you get an integer of 0 or greater, 0 is a valid socket number. If you have a valid socket number all resources on your system allocate to that. Therefore, you need to make sure you call closesocket() to free up those resources. Say that again.
If socket() returns greater than 0 you have to call closesocket() on it. If ever you get a valid socket you have to call closesocket, even if you didn't call socket() to allocate it originally. Gets returned from some of the later calls like accept(). It's a valid socket, you're responsible for cleaning it up.
So the last function here is bind() and that is basically to take a socket and say this socket is connected to this other address, period. Once you bind a socket to it you cannot change who it's communicating to. You would have to destroy and create a new socket.
So go ahead and move on to some of the -- more functions you're likely to use. If you're writing a client, one you're likely to use a lot is connect(), which basically says take my socket, which is the fd over here and try to connect to this given address when you pass one of these address structures and you also pass the size of the structure you're passing in, and that's what it does. It will then return 0 or greater if it was successful and if it fails to return, less than 0. So generally on a client that's what you want to do.
On a server side if you're going to be waiting for people to connect to you, the series of calls you'll make are socket() to create a socket, you'll want to listen() on that socket. That's the next function here where you identify the socket and you identify how big of a queue of connections you want to have fill up behind you.
And then you generally call accept() on that socket, which essentially puts you in a loop and it waits for a connection to come in and when it does it returns a socket and it fills out an address structure that represents the connection on the other side that you can use for information getting from the system.
After you've either connected to a remote socket or if you're a server, someone's connected to you, generally what you want to do is send information back and forth across the connection and you use the send() and recv() functions.
send() again, you identify the socket you're going to send off of. You have a pointer to a buffer that has the information you're going to send. You pass it the size of what you're sending. There's a series of flags you can send -- that you could set, which nine times out of ten again are going to be zero and off the top of my head I don't remember what sort of flags we support.
And again, with recveing you basically call recv() on a given socket. You pass it a buffer to send to fill out with information. You pass it how big that buffer is so it knows, you know, basically not to try to write to memory it doesn't have and again flags.
So again, it's kind of a whirlwind tour of most of the functions that are available. There are a couple more that you'll see in here and there are some things that generally aren't used as much. I didn't show you select() and how select() works.

So I'm going to go ahead and show you some sample code. We're going to go ahead and we're going to create a simple client. For starters I go ahead and I include my two header files. It's a good thing to do so I have the information I need. Going to go ahead and create a new socket, so I create an integer on the stack that represents my socket. I go ahead and -- actually, I didn't compile this code.
I can't do that, by the way. That actually needs to be sock or something like that. I wasn't thinking when I was typing this in. That won't compile because it will actually think it's the socket function. So change that when you write it down. I'm just noticing that. I was up late doing these sorts of things.

So assume this is sock everywhere and so I go ahead and I -- I go ahead and call socket(). I pass it the AF_INET for the family. I say it's a socket stream and I go ahead and use the basic protocol, which is the constant that would also do the same thing as IPPROTO_TCP.
If my socket descriptor comes back as less than 0, I failed and what I do at this point is, assuming this was a function, for example, I would go ahead and return errno. Let me quickly explain what errno is. Instead of having BSD, you know, these socket functions actually returning a meaningful error code, instead what it does it returns less than 0 and sets a global, and this is per thread in our system. It's truly a global on a lot of others, with the actual error code you want.
That error code won't be updated, so whenever something fails it will set errno to a given value and the next time something fails it will reset that value. It doesn't zero it out afterwards, so if you were to successfully return from a function and check errno anyway, it might be -- it will be set to whatever your last error was. So you either want to clear it out or you want to only check it when you actually need to, when you actually have an error in place.
So if I happen to get an error I go ahead and I basically get out of there and report the error. Assuming I have got it successfully -- what we're going to go ahead and do here is we're going to try to make a web connection to be.com, so I want to go ahead and get the address for www.be.com for port 80.
Going to go ahead and create a pointer to a hostent. I call gethostbyname(), that's the name I want. It will go ahead and fill that information in. If host is equal to NULL, then I know there's been some error. I could find out what it is. I don't want to mess with it anymore. I want to go ahead and call closesocket() in my inappropriately named socket and go ahead and return herrno, which is basically very similar to errno, but it works for the DNS functions, and it's basically a long -- there's also a couple functions to actually get a string -- string-based descriptions of the error, but again, you can find that in the system.
So assuming at this point I now got a valid hostent, I'm going to go ahead and try to actually make the structure to go ahead and connect things, so I'm going to go ahead and create an address on the stack. I'm going to set its family to AF_INET, which again is what I want to do.
I'm going to set the port that I want to connect to 80 and then I'm going to set the address to -- going to go ahead and set the address to the address that the host returned to me; that's how I know what it's doing. And again, if you remember from a ways back, the h_addr is actually a char pointer inside the hostent structure, so you do need to make sure to cast it to a long pointer and then take the address off that.
Then I want to be nice so I want to go ahead and zero out the sin_zero member, just to make sure there's no garbage there that someone's going to look at, and I have an address, a remote address I can connect to. So I go ahead and attempt to connect() on the socket, so I pass the socket I want to use.

I have the -- go ahead and pass a pointer to the address and how big it is and see what the result is. If it's less than 0, again I've got an error. I set an error value. I close the socket, which could also return an error, which is why I put it in another variable and return the initial error. That's it.
Assuming everything's good at this point in time I have created a connection from my client to a remote server. I'm going to get to sending and receiving in a little bit.
I'm going to show you the other side of it which again uses socket().
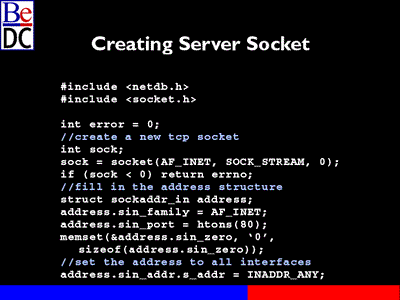
I've created a server socket, pretty much the same sort of thing. I set error = 0 or actually O it looks like, another typo. Go ahead and we'll do the same sort of thing. I'll create a new TCP socket and I'll set it up. If it works, if I actually get a real socket then what I want to do is create the address structure I want to bind my server socket to.
I go ahead and again create it on the stack. I go ahead and fill it out to AF_INET, I set the port to 80 internally. I go ahead and zero out the structure and I am going to bind to -- I'm going to go ahead and set the actual address to any address out there. So INADDR_ANY basically says that for every interface I've got, if I've got multiple Ethernet connections for example, it will go ahead and bind this socket to all of them.
You could also go through and actually there are some settings functions to actually see what the IP numbers of your given computer are and convert those to the long and just go ahead and just bind against that one.

So at this point we'll go ahead and bind(). We take the socket, we're going to bind it to port 80, put out the structure. Go ahead and very simply pass it to the bind() function and if bind() returns less than 0, I will go ahead and set the error to errno, close the socket and return. Otherwise we can assume that we've successfully bound the server socket and we can start listening on it.

So I go ahead and call listen() and basically 10 is generally a pretty good number to use. Some people use 5 for the backlog. Call listen() on the socket and go ahead and listen for up to 10. Again, if we get an error we go ahead and set the error and make sure to close out the socket and move on.
If we have -- if we're successful at this point what will happen is basically something that's ready to accept connections coming in and we'll be waiting for them. So we want to go ahead and generally you'll want to have this a separate thread, so you'll want to go ahead and sit in a loop that says I'm going to wait for a connection to come in. It will call accept() and pass all the appropriate information you see here at the bottom. It will just keep looping. It will accept a socket and when it gets a socket it will need to do something and so it will handle the client connection here and a lot of times that will involve passing that off to something else. Because generally what you'll get is what I have actually is error here is if it is successful, that will be an actual valid socket token and at that point in time I can hand that off to some other thread to handle things, and generally you want to pass it off to another thread so you can immediately go back into the loop.
I had listed here -- keep pointing over here, you can't see there. I had listed here a stop accepting. Generally you'll be sitting in this loop forever and at some point in your application you may need to quit and at that point in time you may need to set some sort of flag that says I'm quitting now and you'll just check that each time you go through the loop.
You can also interrupt a socket. I'm not going to go into how to do that. If you're curious of other ways of breaking yourself out of that, if you don't have a connection, write me at devsupport. There's some people out there. It involves basically calling another socket function that will break that thread out and basically return an error from accept(), which would go ahead and break you out of the whole loop.
So at this point in time we've got everything up and running. You've got a client on one side, a server on the other we want to actually send data on now. What time is it? How much time do I have left? Okay.
This is just a generic function that will send data, send a certain amount of data on a socket. It's a wrapper for actual socket calls and again, ignore the int socket, it's just perpetually everywhere in here.
Basically, what we're going to do in this while loop is we're going to go ahead and we're going to keep track of the number of bytes that we have actually succeeded in sending, the number of bytes that are left to send, keep track of the result of my send calls and basically have a block size.
And what the loop is going to do, which I'll get to in the next slide, is actually going to send data out on the socket in 8K chunks, until you either run into an error, in which case you just backup and give up at this point in this simple code or until you have a chunk to send that's less than 8K, in which case you'll just send whatever's left.
If everything works out fine, this function will return the total amount of data that was sent, otherwise it's going to return an error.

Let me actually get to the while loop. It's just a little bit confusing, which is why I wanted to explain it earlier.
So as long as result is equal to B_OK, as long as we've successfully sent something and bytes we've sent is less than the buffer size, meaning we still have data left to send, we're going to go ahead and enter this loop and if bytes are left are less than the block size, we're just going to go ahead and make a call to send() and we're going to go ahead and send on the socket.
Where we're going to send from is the beginning of the buffer, plus however much we've already sent. That's going to be the starting point we're going to work from and how much we're going to send in this case, in the top case is whatever's left to send because it's less than my block size.
If what I have left to send is not less than my block size, we go ahead and do the same sort of function but send a block size of information. Then after we've gone through the send we're going to basically evaluate -- if the number of bytes we currently tried to send is less than 0 it means we have an error, we go ahead and return errno and just back out of the whole thing. If the -- that will break us out of this while loop and then on the other page we'll go ahead and return the appropriate error.
If the number of bytes is greater than 0 or actually equal to 0, we want to go ahead and basically say we were successful in doing what we want. We update our counters for how much we've sent, how much we've left. Go ahead, back up to the top of the loop.
This function will go ahead and take this chunk of data, whatever you want to send, send it at 8K chunks until it runs into an error or until its done and it will then return to you how much it's sent or the actual error code that you ran into.
Do the same sort of thing in the receiving loop, but things are a little bit different. We've got the same amount of information. We're going to keep track of how much information we've received, the number of bytes we received at a given call.
We've also got another piece of information here called zero_count. One thing I need to explain about send() and recv(), these are blocking calls. That means if there's no data either to send or receive, it will block. It will wait. Send(), if you're going to send information out, that call -- that call doesn't return until an error occurs and it tells you or until that information has actually been sent to the underlying network.
Same thing with recv(), but it's a little trickier. When you're sending you know how much information you're going to send, so you can keep track of how much is left. When you're receiving most times you don't know how much information there is.
So what you don't want to do is allocate a buffer and say I'm going to go get something and grab it and fill it out, and I'm going to get some more and grab it and fill it up, and if that last chunk had empty space in it and there's nothing left to grab, if you go back to try to grab more your thread will block until there's more data on that socket. And again, most of the time you don't know how much there is, so what we're actually going to do is use a call I didn't show you before and which is the setsockop() call and you can pass it a bunch of parameters.
Essentially what this function does is it says when you're receiving this information if there's no information to receive, immediately return with an error. Go ahead and return with a negative number so that I know.

And what we're going to do for the rest of this is in the while loop we're going to go ahead and keep trying to receive information and if we basically get an error that there's nothing left to receive, we're going to start counting and after five times that we haven't received anything, we're going to assume that there's really no more data that I want to get and break out of it.
I do think this is probably not the best way to do it. It works. I'm going to default to the network, the rest of the networking team to hopefully sometime in the future try to come up with a better solution for this, but in the meantime this will work. And at the end we'll go ahead and set the socket back to blocking so that when you're ready to send it will be blocking.
So again, let's show this code. We're going to get up to buf_size bytes from the socket or until five -- actually, five consecutive times without getting anything.
So we're going to enter the while loop while bytes received is less than buf_size, while we still have space left in our buffer to fill and we've been successful, going to be okay or result says gee, you're supposed to be blocking and our count of how many times we've not gotten anything is less than five, we're going to go ahead and make the call to receive. And again, it's going to work the same way. We're going to pass it the socket. We're going to pass it -- actually should be bytes_received here. Copied a page of that from the other code. We should really run these things before we put them up on the slides.
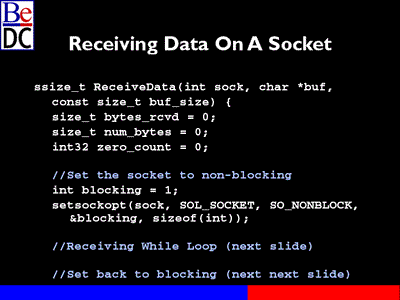
So you go ahead and take -- wherever you're going to receive the data into, where's the recv() function going to copy it into, it's going to copy it at the beginning of the buffer, plus however many bytes we received. So go ahead and change that before we put it up on the web. And how much -- how much space is left that it can copy into. Well, that's how much -- how big the buffer size is, plus what we've already received not sent again there.
If number of bytes is less than 0, which means we have some form of error, we're going to go ahead and increment the 0 count, else we're going to adjust the bytes received and reset the 0 count to 0. We're going to set the results equal to errno, which if we -- is another problem. And that's simply because this won't get reset.
What really needs to happen at this loop is at the beginning we need to set errno equal to B_OK, so that the first time we run into an error we don't automatically every time we check errno assume that there's an error there. So again, in your notes make comments and before this goes up on the web I'll go ahead and update this slide.
But again, basically, you loop through until either your buffer that you set aside for receiving information is filled, or until you get a real error or until you've looped for five times and there's no information for you to get.

And then finally at the end we go ahead and set the socket back to blocking, with the same sort of call and if result is equal to B_OK or result is equal to block, we're going to return basically the last result that we had where either that everything was fine or that we just finished blocking. We're going to return how much information we received all together or we're going to return whatever other error we got that's set in result.
That's it, a whirlwind tour of how you're supposed to go ahead and send and receive.

So I'm ready to take the questions that people had and again, my apologies for the errors in bits of sample code. Yes, sir, you had a question?
(Inaudible question.)
Stephen Beaulieu: The question is sending and basically getting information about the Pop account inside the Mail Kit.
One of the reasons why I wasn't going to go into checking mail is currently the way the Mail Kit is implemented there is only one account that can be set up in the system. That means you have one mail account that is checked.
Now, there are -- there are a couple function calls, notably set and get the pop account, that take an index. In the future support of having multiple accounts you're going to deal with, the documentation will go ahead and say that only 0 is valid right now, because we currently don't support multiple connections.
That's something I hope that some of the team -- and that's actually probably not with the networking team, some other people have done that -- will go ahead and do the support or that I can get it done or something. But obviously, that is something that's important, because right now different mail clients, for example, both Adam and Mail It, two of the popular mail clients that are out there. Neither of them use the built-in mail_daemon, for various reasons, and part of those reasons is because it doesn't support multiple pop accounts.
We would like to -- I would like to see the Mail Kit used as the standard way of handling mail on the system, because it's convenient and lots of people can go ahead and use it for other applications like what I showed you earlier. To get to that point there are some improvements that have to be made; that's one of the reasons didn't go over checking mail.
Back in the back, sir.
(Inaudible question.)
Stephen Beaulieu: The question is I had mentioned earlier that sockets were not inherited over fork(). And the question had been well, if we're going ahead and spawn a kernel thread, how do I get the socket descriptor into the thread or the thread function or the object that I've created running in its own thread to handle these things.
It won't happen automatically. You will either -- when you create a kernel thread or what I would actually suggest people do is there are a couple different C++ libraries that people have out there.
Howard, you have what, Nettle?
A Speaker: Yeah, Nettle doesn't have anything to do with threads--
Stephen Beaulieu: Okay. What I would suggest people do is hopefully someone will write a threaded socket kit. I had one when I was back at Purity writing Charlotte.
Basically, when you go ahead and spawn a thread you need to identify the function that that thread's going to run. That function itself can take an argument and you can pass it in that way or you can have another function call that's associated with that thread that will fill in that piece of information, or that thread is automatically going to look for a global that will be some socket, or if you actually wrap it in a class, which is what I would suggest, when you go ahead and create that class you just pass it the identifier. The socket identifier is valid, it has nothing to do with what thread is running. It's valid across the entire system. We just want the reading and writing and all the options to happen in its own thread per socket, because that's generally the most efficient way in our system right now.
Do you have some follow-up on that?
(Inaudible question.)
Stephen Beaulieu: fork() will work, but the expected behavior under fork() is that all of the global data associated with the application at that point in time will be passed through to the child process. That's what doesn't happen.
Therefore, you can call fork(), but you're going to have garbage inside of -- inside of the information, so that's why we suggest you not do that. That's an expensive process anyway. It is much, much more likely and efficient to just spawn another thread using our threading system, because we have a very lightweight and efficient threading system.
(Inaudible comment.)
Stephen Beaulieu: Basically, Howard was saying that Metrowerks ships with a thread class that uses the Be thread kernel API and you could basically do a subclass or modify that class to take a socket as a member variable, pass it to the constructor and write your functions appropriately. That would be a lightweight way to do it.
Go ahead and take this question up here first.
A Speaker: It's an unbelievably naive question, but it has to do with the TCP, I think you called it. When you're sending a packet, lay it down that way, doesn't that packet know how images it is? So when it's getting received... (inaudible.)
Stephen Beaulieu: Excuse me. The question was inside the TCP protocol itself you actually know what the size of the buffers are and this is, unfortunately, going to be the last question, because Peter has to come in here and I'll take other questions outside.
It knows internally, TCP, the size of the packet you're sending, so why can't you use that information inside your received call and know how much is being sent.
Yes, you do know how much has been sent to you. The idea is, though, that a web transaction, generally those are like 512-byte things, they're very, very small packets. If you're downloading a web page, the web page could be 50K, the web page could be a meg. You have no idea how big your upper-level protocol, how much information's supposed to be sent and considered one transaction, because there's no mechanism for identifying that I'm about to send 500 million bytes, you know, so that's why you have to sit in the loop.
And again, we had a lot of information to go through. I will go ahead and continue answering questions outside and let Peter go ahead and get in on his session. Thank you very much.
(Session concluded.)