
Approaching the Be File System
Dominic Giampaolo
|
March '98 Be Developers' Conference Approaching the Be File System Dominic Giampaolo |

Dominic Giampaolo: Okay. I'm Dominic Giampaolo. I wrote the file system, contributed to the file system independent layer (well I argued a lot about it), and I helped with the C++ API. I'm going to be talking about all three of these things. The first thing I'll talk about are the features of BFS, what this means to you as a programmer, what things you do to take advantage of it, and how to get performance out of the file system.

I'll talk about the C API but mostly the C++ API and then the plug-in file system API, which is still as yet undocumented mostly, but we do have sample code and we're willing to work with people since it's a pretty tricky thing to do.

The big things about BFS are that it's a 64-bit file system built to support very images files. Another cool feature is that we support extended file attributes so a file is not just a stream of bytes which is the UNIX model. Attributes allow you to have additional information stored with a file and it's just as efficient to store images amounts of data in attributes like multiple forks of data. Not just resource and data, but you can have the data and you can have any number of other forks that you would like.
You can index attributes so you can say if you receive a piece of E-mail, the "to:" field is indexed, who the E-mail is from is indexed, and you can do queries on that. We'll get to that later. BFS uses B+Trees used for directories and indicies. It's very efficient to open files. B+Trees are used for lookups, indices are done using B+Trees, so it's very efficient to launch an application by signature because it is done with a query. A query does not look over the whole disk, it just uses a B+Tree. The file system is also journaled for better file system integrity. No long file system checks at boot time. The file system is also designed to support sustained high-bandwidth I/O.

Let's talk in more detail about attributes. They're Name/Value pairs. The attribute Comment = "this is cool" has a name (Comment) and the value is "this is cool." This is an example where the attribute value is a string but you can also have arbitrary data, store bitmaps, preview images, whatever. You could store hundreds of megabytes of data in an attribute if you felt like it. The attribute types we support are string, integer, double and raw data; the built-in types such as string, integer, etc can be queried.
You can have an unlimited number of attributes for file. Well it's not really unlimited. Baron one day was screwing around and I think he ran into a problem at about 3 million attributes on a file. I should fix that. If anybody runs into it, let me know. Any size data, of course, in the attribute value. You don't have to be constrained or feel like this might not be stored as efficiently or that it may not be as quick to access. It's, in fact, the same data structure used to represent the file data is used for attributes. You can store information about files in attributes. You can say, "I don't know if this applies to my application." Anybody can store extra information about a file without having to with muck with the file format. GIF is a specific format and I don't know if GIF supports storing gamma ramp information. But you can store that in an attribute if you'd like.
The Tracker stores window position, size, and information like that in attributes. StyledEdit stores its style runs in attributes so that the text of the document remains simple ASCII text, even though it has multiple fonts and different font sizes and colors and so on and so forth. The attributes maintain the style information. BeMail, the "from" field and what field, and so on.

Next is indexing. When you've indexed an attribute, you can query it. That means that you can find things efficiently. You can create an index for an attribute. The mail "from" field is an example. In the BeOS we have a person application to store information about a person such as their name, E-mail address, so on and so forth, all stored in attributes of the file. And you can create indices so you can query for everyone who has a 415 area code because I need to change it to 650 because it just changed recently, or something like that.
There's comparison operators for when you're searching through a query. There is a query language associated with this. The query language supports wild card matching for strings so that you can say, like I said, finding all people that have an area code 415, you search for *415*. This, of course, can be frontended with an GUI as Tracker does or hidden internally in a program.
One thing about the indexes, it's not really a relational database nor is it a query language like SQL. The query language is pretty much straightforward and uses in-fix notation.
I was going to flip over to another work space here and show you a couple things. So as I said, you have -- here are a couple people we have with some interesting names. And they have different attributes about them. If I double click on Mr. Hugh Jorgans, he has a whole bunch of information associated with him, not all of which is filled in. Again, you know, you don't have to fill it in. It's not fixed, attributes can exist or they may not exist. They don't have to. Further, what's actually really cool about all this is that if another application comes along and let's suppose you have a work fax number and a home fax number. That doesn't mean you need to write an entirely new application. You can add that attribute so you can have an application that knows about multiple fax numbers or multiple E-mail addresses for a person, and that application can take advantage of those attributes and the other applications that work with the existing person entity don't have to be changed. So I add something new, that's okay. Everything else continues to work. And if I get a file that has extra attributes on it, it doesn't affect me if the ones I need to know are there.
It's similar to a BMessage where you can add things, arbitrary things to a BMessage. If another app understands what you've added to the BMessage, it can take care of it. The Tracker, of course, has a nice fine panel and the simple way is where you're just searching for a name and it's case in-sensitive. There are more sophisticated queries you can do where you're querying on different sets of attributes. With E-mail I can query on a different set of attributes. For example I can query the "From" field to see if contains JLG and then if I want I can have different conjunctions so it's from JLG or from Alex. So either from = JLG or from = Alex. Of course There's no E-mail from them here but if I want, I can search for them.
Further to give you an actual indication of what the queries look like you can switch the Find panel into Query By Formula mode. This is the query language, which is saying something like, "I want to search 'from' mail, from equal to JLG," and it's done in case sensitive with standard regular expression or -- or put some spaces to read it. You see there's an OR operator, in familiar C syntax, but working with attribute names and values.
You can do things like size greater than a certain size, so if I go back to by name I search for size is greater than, 500 K. You can edit the queries. I can go back to formula mode. Sizes greater than 512,000. It works with numbers and so on. That's what the query language looks like. There's also in R3 a command line tool written by Ficus so I can do, "name equals *e," all files end in "e." I don't know how many that will be. It will print things out. This is actually kind of useful sometimes if you're writing a shell script which wants to use queries. You can do it that way.

Let's go back over to the presentation. The next thing, Journaling. Sometimes there's a lot of confusion about Journaling. Journaling preserves file system integrity, not user system data. Journaling is a mechanism the file system uses if you crash and the power system goes out or anything happens and the machine is rebooted for whatever reason in the middle of writing to the disk, the file system is actually not corrupted. It enables fast boot files, independent of the number of files you have on the disk. Not so much a problem now, but if you have multiple 9-gig drives with hundreds of thousands of files on each of them, the reboot time can get to be significant if you have to check each of those disks as you come up. That's one of the main advantages of journaling.
Journaling can even improve performance which is something that most people wonder how it can be because you're writing twice as much data. Journaling enables you to batch transactions and write images contiguous amounts to disk which is something that disks are good at, instead of having to write through every single time to ensure integrity. Traditionally, UNIX file systems such as the Berkeley fast file system have to write everything through the disk. When you're updating, creating your file, they have to write all the way through the disk and wait for that write to complete and do that several times just to create one file. That's about the slowest thing you can possibly ask a disk to do is write one disk block in three different locations. With Journaling you batch everything in memory and then write one big block out to the journal section of the disk, and later on in batched groups the other transactions will get flushed out to disk. User data is not logged.
So yes, you can lose data. Journaling does not prevent you from writing a whole bunch of data which is sitting in the cache, yanking the plug out. You have a disk cache doing what it's supposed to. So you can't guarantee that the data is not lost. There are ways to do that with functions called fsync and sync which force all the data to disk for sure. And you don't have to worry about that. Transactions happen at most once. You don't have to worry about a file being created twice or deleted twice or anything like that. The log playback is pretty simple and it's independent of disk size and takes about 30 seconds in the worst case where, you know, you've yanked the plug out and you had ten programs writing a whole bunch of stuff to the disk at the same time.

Performance. This is what you really care about, I think perhaps more than anything. How do you get good performance out of the Be File System? Big writes are good. That's always going to be true pretty much of any file system, but to help ensure file continuity, if you're writing small chunks at the time, the file will probably be contiguous on the disk at least in 64 K chunks if at all possible. But you can actually help things along by writing even imagesr chunks.
We found in general 64 K is a good size. You start to see, you know, a fairly significant portion of the disk's bandwidth, but with fast and wide ultra-SCSI disks we found you actually need to go even imagesr buffer sizes to really max out the drive. The difference from 64 K to 512 K buffers was a factor of 2 and we maxed it out about 13 or 14 megabytes per second with a megabyte buffer. That's not always appropriate, but when you're streaming video you can buffer an entire frame or two frames and start to see the maximum bandwidth of the disk that way.
Also, a side effect of doing images I/O's is you bypass the cache. When you're streaming a images amount of data, most systems don't have a provision for bypassing the cache. So your data gets copied into the buffer cache and sent from there to disk. You wind up with this extra copy where instead you could have DMA'd it straight to disk. The cache management hurts you. You wind up with special purpose API's to avoid that. On the BeOS if you do an I/O imagesr than 64 K, it's going straight from the disk right to your user buffer.
You want your I/O's to be multiple file system block size if at all possible. By doing an I/O a multiple of 1 K or imagesr block size, that's going to be much better than doing just, you know, I don't know, 64 or 65,537 bytes. Yes, it's more than 64 K, but that extra byte at the end has to be handled specially. The block is read from disk, the byte you wrote is merged in and it's written back. That's not as ideal as doing a imagesr transfer or multiples of the block size.
Furthermore, on Intel, it turns out not all DMA controllers are created equal and some DMA controllers can't go to byte aligned positions. For this reason it's better if the position that you're in in the file is also multiple of 1 K or imagesr, which is pretty easy if the size that you're always reading is a multiple of 1 K. Easy to ensure that.
This is kind of low level detail that you shouldn't have to worry about and you don't. The system obviously still works correctly if you don't worry about this. It's just you'll see better performance if your buffers are multiple of 1 K in size and your file position is always multiple of at least 1 K in size. That's just a small thing.
A good example is Steve's video demo that records video and audio to disk. He allocates a bitmap, that is slightly imagesr than the video frame and has room for the audio buffer, and it is padded out to a 1 K boundary. He only draws the visible portion of the buffer, tells the audio subscriber to pull the audio data out of a small portion of the bitmap and he always DMA's one whole chunk at a time or reads one whole frame at a time.
A very simple processing loop, but playing a few games like this interleaving the audio and video, can make a significant difference. Each frame of audio is not 64 K so it's not going to be as efficient if you write it out separately.

Okay. Now we'll switch gears and talk a little bit about the file system API's. And once this is done I'll answer questions about any of the different sections. BeOS supports two different API's, standard POSIX, that is POSIX fopen/fread/fwrite calls with your basic file descriptors. Nothing quirky about that. We also have additional extensions in the C API, read attr, write attr, as well as extensions for creating indices and removing indices and iterating through to find which ones are on the disk or attributes are associated with the file.

It's all pretty basic stuff. If you can call read or write, you can figure out read attr or write attr. There's not much to them, it's pretty basic.
The C++ API is generally what BApplications would use; although, you can mix standard POSIX I/O calls from a BApplication and there's no reason that's not efficient or effective or anything like that. Now let's talk about the C++ API design goals.

Really, it was very difficult to design the C++ API, i.e. the storage kit, because there's many different goals that you have and many of them are conflicting. So we're trying to balance efficiency with ease of use. You don't want it to be 15 lines of code to open a file. That would be absurd. You also want it to be efficient at the same time. We're trying to keep consistency between the underlying file system and the API's on top and we also wanted to have transparent support for external file systems.
A question I get a lot from the Mac community is where are file refs or directory IDs. They want a permanent handle to a file that will never go away. You can support that on HFS, but it's not a generally available concept that exists everywhere. We want the API we're using to support many types of file systems, some of which we may not have thought of yet.

The key concepts of the C++ API, are entries and data. There are two distinct concepts. Directories contain named entries. A file called "Quarterly Report" is an entry in a directory. Each entry has associated data so the file "Quarterly Report" has some data associated with it, a string of bytes, as well as any attributes that may be associated with it and so on. There's two distinct concepts here. The named entities that is the things you think of when you think of the file system hierarchy -- these are the entries. The data is the what's stored in each of those named entries. Our class design reflects this.
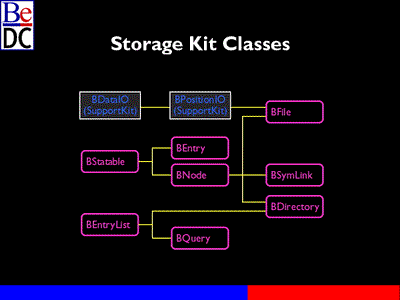
Here is sort of an overview of things. It's not the entire storage kit.. You start with on this side you have BStatAble. The stat function comes from possible terminology, statistics about the file. From there you have BEntry, BNode and further descended from those are BFiles. So these are the parsing. You can do I/O, too. BFile is the data portion of a file. BDirectory lets you iterate through the named entities and so on. The named portions which we don't have a diagram for --
Dominic Giampaolo: Well, we don't have -- well, BPath is another --
A Speaker: Sorry. That's not up there.
Dominic Giampaolo: That's another portion. Manipulating the names -- I'm having a hard time talking. The named portions from BPath and there's entry refs which are not the actual data of the file. It's more a reference to a particular file on the disk. It can refer to either a file or directory. When you're thinking of hierarchy, names, you start at the top and on the BeOS, I can flip over here, the window. To the top level directory, there's just a bunch of names. They all happen to be folders, but just a bunch of names that would correspond.

You could have a BEntry referred to the apps directory or BeOS directory. Then it allows you access to the name and location of the hierarchy. You can change the entry name, get the parent directory, move it or remove it. But you can't do I/O to the file. This is the distinction we make between the two things.

The BFile class allows you to read and write data. You can do it from an entry ref, read and write attributes. You can't remove a file just having a BFile. That's not currently possible.

The BDirectory class allows you to iterate through everything in a directory, a folder, find specific entries as well as create new entries. So you can -- you get back a BFile when you create an entry in the BDirectory. You can tell I spend most of my time doing code.

The BQuery class allows you access to the queries we alluded to you. The programmatic interface. Everything that the Tracker is doing is all public API's, no secret magic. There's a string-based infix notation that the file system uses underneath all this as well as stack-based push/pop interface. You saw me interfacing in the find panel, "mail from equals JLG or mail from equals Alex," so on. There's also stack-based push/pop interface so you can push operators, "push mail from, * JLG, push equals" and that gets turned into it. There are live queries. Live queries are used by the Tracker all over the place. Incoming E-mail, when new files enter or leave the set of files that match your query, the query is updated. You receive notifications about this.
Let me go back to this other side. We have another thing that is similar to queries but a little bit different called a node monitor. It is another kind of useful feature from a programing standpoint. Node monitor lets you watch files. "I need to know if this file changes," you can say. "If it's been written to, if it's been deleted, if this directory gets a new file dropped into it, I want to receive these messages." You receive it through a standard Be face interface. If you have some program and you're editing a document and it has compound components in it, you have GIF image pulled in from off disk, you can monitor that file. If it's updated, if the paint program updates it, your program can receive notification of the file saved, you reload the file and it's updated into your app. This is a pretty cool feature. It's a polling thing. It tells you when things have actually happened. So that's a parallel, the node monitor is a parallel to the BQuery class.

References to entries. We talked a little bit about BFile and BDirectory. We have references, BPath and entry ref, or references to objects refer to something on the disk. Generally, you'll get an entry ref and a BMessage and you can use that to get access to that file, so drag and draw gives you an entry ref and you can substitute that into your BFile and access the data dropped on you.
A Speaker: Where is BFile in the hierarchy?
A Speaker: It stands by itself.
Dominic Giampaolo: Pretty much. Pretty much a straight manipulation. It doesn't do anything else. It knows about directory separators and so on and so forth. BPath or entry remember can be used to create BEntry objects. If somebody causes you, on command, to stream when they run, create a BFile from that, or if you receive a drag and drop message that has an entry ref, you can create a BFile and access the data.

File and directory information. Basic information, again, the statable information, is it a file, is it a directory, what is the size of it, so on and so forth. Also a POSIX-style stat struct. The C++ API are the same concepts. Really in the end it is the POSIX stuff.

Now we'll switch gears, talk about plug-in file systems. Plug-in file systems provide access to different disk layouts, so different disk layouts, BFS, HFS, NTFS, DOS, NFS, Berkeley file, a whole plethora. We don't want to hardload that into the kernel. It would bloat it out unbelievably. Those are done through an add-on API, very similar to drivers, although much more extensive. The file system provides the extraction of files and directories. So you can use all the other API's that we just talked about to manipulate these things. Of course, the file system can be mounted and unmounted. We have a built-in mounting tool.
A Speaker: Is the plug-in file system similar to dynamic module loading of LINUX?
Dominic Giampaolo: I'm sorry? The question is, is a plug-in file system similar to a dynamic module in LINUX. They can actually take over system calls and so forth. And plug-in file systems have really a very specific API, which is the next slide. So a set of about 55 calls that basically lets you iterate through directories, look up names, perform I/O, read and write, manage attributes, queries and so on.

Of course, 55 calls, not even BFS implements every single one of those. There's a few still left undone. You don't have to fully implement the API. In fact, something like the ISO 9660 file system I think only implements 20 or 25 calls that are needed. Many of them are repetitive in the sense that you have to be able to iterate through a directory. And if you were implementing attributes as well, you iterate through attributes, the same style of API as directories
There's an open directory, read the next directory entry, go back to the beginning of the directory and then close the directory. So that is the sets of calls are duplicated for attributes. There's open attribute directory, you know, read the next attribute that's on this file. So they are very similar. So one set of them for directories, you can go back and do the others. It's nice you don't have to fully implement everything.

As you see on the next slide, you can also do virtual file systems which are kind of cool. The file system doesn't necessarily have to be something on disk. In BeOS we have /dev and /pipe, which are virtual file systems, and /dev knows about device drivers and loads them, publishes their names so you can actually see what devices are hooked up. Actually, I might as well switch over here and show.
A Speaker: Do you have a font terminal
Dominic Giampaolo: Sure. imagesr?
A Speaker: imagesr.
Dominic Giampaolo: Is that good enough or a little too big? Of course, Baron owns all the files. There's a bunch of different devices, some of which have older names we're trying to phase out as we move to a slightly more clean configuration. If you look, /dev/disk where all the disk devices are. We have floppy, IDE and SCSI, an Intel machine. There are two bus interfaces, CD IDE, master and slave disks. Within each of those entries for partitions and zero zero and raw. The full path /dev/disk/IDE master. There's the raw disk which is, of course, the entire, from block zero to the size of the disk, and the partitions are created as virtual devices in there, so the /dev file system manages all this. There's never anything stored. It's all created and maintained in memory. So plug-in file systems can actually do some pretty nifty things.

Another example would be a /proc file system, UNIX debugging as well as a whole passel of other things. /proc would allow you to access a process to manipulate its registers and so on and so forth. You can do it through read/write interface similar to a file system, but it doesn't have to be on disk anywhere. Let's see. So some of the issues with writing a file system for the BeOS, not something that's documented, mainly because we haven't had time, although we do intend to. We have published source code for the ISO 9660. We are willing to work with people. The BeOS is highly multithreaded, very little locking done at higher levels. BFS, that happens all the time. You will have many people in the file system at the same time so you can have, you know, four or five threads reading from disk and they're all the way where they're blocked at the lowest level, some waiting for access to the disk controller. That's, of course, you have to serialize access to hardware. Even that is something we're working towards moving away from.
A Speaker: That's similar to the way System 5 implemented system level, low level locking and unlocking for use?
Dominic Giampaolo: The question is, was this similar to the way System 5 implemented locking for use. To be honest, I'm not sure. I'm not familiar with exactly what you're referring to. We -- the file system has to manage its own data structures, has to lock them and unlock them as it sees fit. BFS has to be as multithread as possible. If two people have different files where they're reading from, 16 channels of audio, both of those guys will come in through the file system, traverse the system, find the file block they're supposed to be reading, go and read that from the disk, at which point they have to be serialized to access the disk.
A Speaker: So it's like?
Dominic Giampaolo: Of course if you have multiple people writing to the same file, then they're serialized. Multiple people writing to the same files can occur mostly independently. Some file systems have to be locked when you're manipulating, allocating blocks in bitmap from the disk. That has to be locked. Only one of them. So that can't happen independently. Locking is a responsibility of the file system. You can, you know, do that the easy way which is put a big lock around the whole file system, only one person in there the whole time, CD-ROMS, it's acceptable. You probably don't want multiple people in the file system at the same time because you wind up thrashing the heads around, the read/write mechanism, read on the CD.
So there's re-entry issues, of course, because when a file is removed, first the name is removed from the directory and then the file is actually unlinked, its resource is freed up. You can come back in. If you're swapping to a particular file system, you have to be careful when you're doing I/O if you're using the swap file on there. There's some interaction with the memory system.
That's something if someone was wanting to use a file system of that sophistication, we would have to work closely together. Even we are still figuring out some of the issues that arise. The R3 actually saw a couple of really obscure things pop up, which were fixed, but it's tricky.

So overall summary. Let's see. BFS supports attributes, indices, journaling, queries, high-bandwidth I/O and 64 bit volumes and files. That's a lot of buzz words and so on, but it translates into features you can use in your programs to make your apps more rich. You can use attributes to store extra information about file, you can index that information so later you can retrieve it very efficiently. Journaling, you're guaranteed fast boot time, your file system won't get corrupted very easily. It takes an awful lot these days to corrupt a BFS file system. In fact, our testing for R3 on Intel, we could not, over several days of testing, where we run lots of heavy-duty stress tests, we were not able to even corrupt a single disk. I was pretty happy with that. Pretty good. Things, situations where you fill the disk up 100 percent and then just keep hammering it for two or three days, keep trying to fill it up. You hit lots of corner cases, my disk is full and delete a file. So we're pretty -- journaling is a good thing.
Queries, like I said, get you access to information quickly so you don't have to necessarily keep track of everything yourself. You can let the file system do it for you.
High-bandwidth I/O by using images buffers, you're going to see 90 to 95 percent raw bandwidth. And if you buy a new disk, format it with BFS and start laying down video, you're going to get as much as that drive can deliver. On the IBM DeskStar, IDE drives I think they're rated at 6 megabytes a second, 5.8 through the file system, 13 and a half megabytes out of the 14 and a half megabyte drives. So we're pretty happy with that. The file system is not introducing a lot of overhead. Those are ideal cases with a clean file system. But even so, the data structure the file system uses, approach taken to lay out data, help ensure things contiguous, the applications are also helping by writing images buffers. You'll even see that over the long-term.
Moving on to the API's we talked about, the POSIX as well as object-oriented API. No performance difference. You can use one or the other depending what you see fit. If you're a C++ hacker and what you want to do, there's BFile and BPath and BEntry, so on and so forth. If you're an old-time UNIX weenie, your standard fopen, fread and fwrite are there and it works as expected, and in memory entities. And I think that about wraps it up. I probably whizzed through that awfully quickly. But I'll take questions now. Right over there?
A Speaker: What's the fragmentation story?
Dominic Giampaolo: We make a big effort to try to keep files contiguous by preallocating space for them. Almost all files -- sorry. If you look at a breakdown at most files on a disk, most of them tend to be less than 16 to 32 K and almost all of them, as in 95 percent or more, are less than 64 K because we preallocate space for those, those are all going to be contiguous on disk.
One other thing I guess I should mention, the things like HPFS where they had the block size problem, you know, 32 K allocated for one byte file, BFS doesn't have any of those problems. The minimum block size is 1 K. At most you're going to have 1,023 bytes of wasted space. Try to reduce fragmentation that way as well. You're efficiently using the disk space. You don't have 32 K where you don't need. The allocation is trimmed back.
images files. images files, writing them one byte at a time still allocated 64 at a time. We haven't seen it get fragmented terribly bad to, what it boils down to.
A Speaker: In terms of moving the BFiles to one system, UNIX, whatever, what happens to the --
Dominic Giampaolo: FTP.
A Speaker: Repeat the question.
Dominic Giampaolo: What happens if you move files from the BeOS BFile system to another system that doesn't support attributes, if you just use FTP, the attributes are not preserved. FTP has the data string. It would be hard to coerce it to do something different. The zip tool which Chris Verboth has extended to support attributes because they support those for HPFS from OS2, which has extended attributes, preserved attributes, you can zip up, move it to LINUX and zip file, put it on another system, they are preserved. Anything you download from BeWare, that's what has happened, a zip file, a bunch of stuff, put on a server.
A Speaker: With NFS, support to Be, I know that's a different program, slightly, but have you seen this work?
Dominic Giampaolo: Yeah, I've seen Be NFS, I think Andreas Huber. It's pretty neat. I would like to actually talk with Andreas, but it doesn't work for me 100 percent of the time. But, yeah, he's done it and it seems to work. I can mount my LINUX drive or somebody else's LINUX drive and access it.
A Speaker: Does it preserve attributes?
Dominic Giampaolo: I don't know.
A Speaker: Repeat the questions, please.
Dominic Giampaolo: He says does that preserve attributes if you mount an NFS drive between Be and LINUX. NFS does have support for extended file attributes. I don't know if he's taking advantage of that protocol.
A Speaker: When you do a format, can the disks still set the block size? Any reason we couldn't set it down to 512 or up to 2048?
Dominic Giampaolo: The question is, when you format a new disk, you can set the block size to different sizes. Why would you set it to different sizes? The default is there for a reason. It makes a lot of sense, fits with things. The reason on very images disks or CD-ROMS where the block size of the device is 2 K and you can't read any less than that, you might want to set it for 2 K. If you're formatting a disk, an example, when we burn the BeOS CD's, we create those with 2 K blocks because they'll eventually wind up on a CD, burned to a CD, and a CD doesn't really read less than 2,048 bytes for a single block. You can't set the block size for 512. The minimum is 1 K. So if you had one of those fancy new 27-gig drives, a 2 K block file system might actually work out better in that situation for imagesr files and so on. In the back?
A Speaker: When are we going to see the like fsync moved into BFiles and stuff?
Dominic Giampaolo: It will happen for R4. It's so trivial to do. It was just an oversight it wasn't there in the first place. Another oversight, we didn't do it for R3. But fsync will definitely be in the BFile for R4.
A Speaker: The question would be, I guess is there a lot of data and have it queued up and at a certain point later have the full path?
Dominic Giampaolo: The question is, if you queue up a bunch of data --
A Speaker: Mixing it through.
Dominic Giampaolo: Once you call fsync the data, any data that you've written to the file is flushed to the disk. The entire file is pushed out and written to disk. So you can write, you know, 10 bytes, 100 bytes, 5 K, another hundred bytes, you call fsync, all those writes are pushed, guaranteed to be on disk before that call returns.
A Speaker: Can you use attributes on a virtual file system?
Dominic Giampaolo: Sure. It fills in the, I forget what it is, maybe eight or nine calls between iterating through them and reading and writing them and removing them and so on, yes, you could do that in virtual file system. In fact, I was just talking with Trey about doing that.
A Speaker: Could you also use the query mechanism on the virtual file system?
Dominic Giampaolo: The file system API applies to any file system. You could write an entire in-memory file system, an interesting exercise, that implemented the full file system API, but only on in-memory data structure. Yes, you could do that. It would be a fair bit of work because you have to parse the queries. The parsing engine of BFS is perhaps the imagesst single piece of code in it, so it's quite a bit of work. You know, live queries are another aspect of it and so on. So it would -- not to dissuade you, but it would be a lot of work, but it's fully possible.
A Speaker: I've got a PowerMac with BeOS installed on a partition on a hard drive. What I want to do is delete the other partition, two partitions on one drive and then extend the Be partition. Is there a way to do that?
Dominic Giampaolo: The question is can you repartition the BFS, drive with BFS on it to make the BFS partition imagesr. I applaud you for wanting to do that, but there's no way to do that right now.
A Speaker: Reinitializing.
Dominic Giampaolo: Or create another BFS partition, the one you want to delete, make it a BFS partition. You lose a little bit of space for the extra things that are there, but you have two separate partitions that are equivalently the same size. The overhead of creating a file system with Be where the BFile system is pretty small, about 2 and a half megabytes or something like that. So if you have 100 megs and you create a BFile system, you have about 97 and a half megs available for data to store. Uh-huh?
A Speaker: I was interested in issues that arose the other day on the Intel side talking about the Big-endian file system stuff and the Little-endian file system stuff. I thought this would be the place to really see about those issues.
Dominic Giampaolo: So the question is the differences between Big-endian BFS and Little-endian BFS between the PowerMac version and the Intel version. Right now you cannot read file systems created on one. If you take a Zip drive from a PowerMac and put it into an Intel system, it won't be read. That's something I need to address for R4 and maybe I can get Ficus to do it. I don't know. It does need to be done. Something that we're going to have to address at some point.
A Speaker: What I was interested in, I realize it needs to be done, what I mean to ask is how do we find ourselves in that position in terms of having a file system that is different on that level. As I understand it, for other things like NFS they're on different platforms, the file system is essentially the same. It's an IE question.
Dominic Giampaolo: The question is, how do you get yourself into that position. The data written is written into the native, all native format. So if you're a Big-endian processor when you write an integer, stored memory, stored on disk, Big-endian. If you would read it back on a Little-endian system, the data is preserved so the number one, value one stored in integer is really several million or several billion in hexadecimal. So that needs to be translated for the two to be compatible. There has to be hooks in there that let you catch the data, translate it to the native format, let you use it. And then when it's written back to disk, it has to be translated back to the other endian format.
A Speaker: So the way to do that would be to insert the floppy or Zip drive or mount the external drive.
Dominic Giampaolo: This might be better to take off line. I can explain it to you in more detail.
A Speaker: One of the things, if I might, we're not allowed in this situation. There is a major operating system from the company further north up the coast that has similar issues relating to natural page sizes, the CPU. They have a problem too with taking disks from one machine, one architecture, and moving it to another.
Dominic Giampaolo: Other questions?
A Speaker: It's unfortunate.
Dominic Giampaolo: Michael?
A Speaker: Yeah. You talked about getting 95 to 99 percent with the BeOS. How does that compare to other operating systems?
Dominic Giampaolo: The only one I really have direct experience with that I've been able to measure that is under IRECS. I was writing raw video, 720 by 486 resolution, 32 bits per pixel, which is basically 42 megabytes per second, and they had 12 disks striped over three SCSI-wide controllers, give you enough bandwidth, those SCSI controllers. I was able to only get 80 to 85 percent of the disk bandwidth under IRECS with FXS with their file system, so I was pretty pleased we topped that out rather well. I'm sure on a clean disk -- actually, a clean file system, other people might do as well. They really should. Of course, we have the advantage that we're directly DMA to disk, we're not going through the buffer cache. Not really a whole lot fancy you have to do. On your IRECS, I had to do a lot of special purpose API and function calls to enable various features. Yes? All the way in the back.
A Speaker: Numbers for the SCSI disk?
Dominic Giampaolo: Well, on PowerMac we get -- we don't do synchronous transfers on the SCSI box on PowerMacs. Out of the 4 and a half megabytes per second we'll get, just accessing the raw device, again, similar numbers. So in terms of absolute numbers, the max I've seen on the disk of a PowerMac is about 4 megabytes per second, sustained. When we talk about sustained FBS, we're not just doing like 500 K file. We do like 100 megabytes or, you know, even some of the imagesr drives on the Seagate Cheetah, a 9-gig drive, we did 13 megabytes a second over a 2 or 3-gig file. So on the Adaptec fast-wide controller we're able to get sustained transfers of 13 megabytes per second with very images buffers. If you're using a standard 64 K buffer, you get 6 megs a second or so. That's an interesting behavior of the drive more than the file system. Yes?
A Speaker: I've heard reports that BFS slows down considerably when you have a lot of files. Is that true?
Dominic Giampaolo: The bench marks people have run tend to create like 10,000 files of the same size. And what happens there, is that, you know, for a bench mark that's sort of interesting, but the indices that BFS uses don't deal terribly well with many files that have the same value for the attribute. So the name size and last modification time of the file are all indexed implicitly for you so you can query the name and size of the file. When you create 10,000 files all the same size, the size index winds up with 10,000 duplicates for a zero-byte file, so that doesn't perform as well. It still works and everything is fine. When you get 10,000, actually it is still reasonable. When you get into 100,000 files, all of the same value, then it starts to not perform really very well at all.
There is a secret undocumented option to create a file system with no indices so that nothing is indexed and you can't index it. You still have attributes but you can't index them. With that, the performance is pretty astounding actually, not something you would expect people to use. The underlying data systems of the file system are still pretty sound. The indexing, there's a penalty paid there. But we want to provide the extra richness so we choose to pay that penalty.
A Speaker: In the future when drive sizes get to be up in the tera bytes, how do you do something when the drive is packed with a lot of small-sized files?
Dominic Giampaolo: It depends on the query. If you want to touch every single file, it will take a while. You have to go and read every single one. If you have a million files and you want to find all files whose name is equal to foo, you're not using wild cards and so on, that is actually going to be very fast. Even using a query that had wild cards, it's still going to be faster than going through all directories and looking at all the files directly. Under UNIX you use the find tool and look at every file. That has to read a lot more data. The B+Tree is much smaller. In fact, I have a couple ideas about improving the performance of those even more. Oh, we have to wrap up. Thank you.
