

GEOFF WOODCOCK: I'm Geoff Woodcock. I work in DTS for Be, and we're going to talk about networking. As far as the level of this discussion, it's very introductory. If you've already done TCP/IP programming, you're probably not going to see a lot of new material here. But if you're from the Mac world and you haven't really done a lot of Berkeley sockets kind of stuff, you might find it useful.
How many read the Newsletter? (Show of hands) So, I'm William's puppy. (Laughter)

We'll go to the first slide. This is our agenda. We're just going to start off with introduction to client server concepts and run through some simple code examples, and then we're going to talk a little bit about Berkeley sockets and then just give you some general advice on writing network programs for the BeOS.

So, there are two types of network protocols that you commonly hear about, UDP and TCP, and they're very different. UDP is what they call a connectionless datagram socket, and the idea there is there's no, like, live connection between two points. At any point in time you can say, send to some UDP socket, or receive from some UDP socket, and you will get one piece of data or a datagram. So it's very low level. There isn't this idea of a real connection at all.
And also things like error checking and packet ordering, if you send two packets in UDP, the one that you send first may not be the one that arrives first. So if you need that kind of stuff, which most people usually do, you have to implement that yourself on top of UDP. The advantage of it is that you can get orders of magnitude more connections with UDP on a machine than you can with TCP/IP.
So moving on to TCP, it's more of a connection-oriented stream socket. It is like making a phone call; once you make the connection, you don't have to worry about how stuff is getting to the other end, whether or not stuff is going to get there in the right order, and if a packet gets lost, is it going to be resent. Those are all things that the TCP layer takes care of for you. So it's a lot easier to work with. But the problem is, you pay for that in terms of memory. And I have heard various estimates, usually on the order of hundreds of connections are the realistic limit for most machines with TCP/IP. So big difference between that and UDP.

Okay. So, the rest of the talk is pretty much going to focus on TCP/IP. A lot of the same concepts can apply for UDP, but I think what most people are interested in working with is TCP/IP, so that's what we're going to talk about.
And, you know, the first thing you worry about is how you make connections with servers and clients, and there is just a mantra that you go through in each case to get the connection set up. And in the case of a server, you have to ask for a socket ID, socket descriptor, with a socket call. And then you have to connect that socket descriptor to a local network interface with bind. And then you have to indicate that you're ready to start listening for client connections with the listen function.
And once you've done that, you can call accept, and that's where you will enter a loop, calling accept and getting a client connection in hand. And that's where you will be doing accept, and then sending and receiving with a client. And when you're done, you call close socket.
Now, the client's a little simpler. He calls socket again to get a socket descriptor, and then he calls connect to connect to a remote interface on the server machine. Of course, it could be local. You could be using loopback, but conceptually... And then he does send and receive to communicate with the server, and then he calls close socket.

So, here are some gory details. This is just a little utility function for converting some of the nasty stuff that you get, that you have to set up into a sock addr struct. This sock addr struct is like the thing that says what you want to connect to.

So, in this case, you have, for example, a client wanting to connect to a server. He gets a string that represents a host name. And the first transmission that happens is you call gethostbyname and convert the host name to a host end struct.
Now, if you instead have a string that is an IP address, you can pass that in to gethostbyname, and it will work just as well to give you a filled-in host end struct.
And then down here you specify the family. The family is always AF_INET for BeOS right now. So you don't really need to worry about that too much.
And then the port. The port is something that in this case is passed into the function, and that's the port that you want to connect to. So, in the case of the server, it's the port that you want to listen for connections on. In the case of the client, it's the port on the remote machine.
So you really have two major pieces of information that specify the connection: What machine do you want to connect to and what port on that machine do you want to connect to. And the port -- it's just a number, and they assign different services different numbers. Like, FTP and HTTP and everything else, Telnet, they all have their own port numbers.
So, one thing that's going to become important in the future is, you see this htons column for port? That's host to network short, and somewhere there are calls to convert data from the host endianness to the network endianness for different sizes and to do the reverse transformation.
So, in a lot of cases, that does nothing, because they're the same; but, you know, when we have Intel, we have PowerPC, you're going to need to have that stuff in there for your code to work on both platforms.
The last thing is just pulling this h addr piece out of the host end struct and placing it into the sock addr struct's s addr. And I would like to point out, you know, this is real specific stuff. This is the kind of stuff that you can put it in a function and it is never going to change.
Okay. So creating a client using this little subroutine. You can see at the top, making a socket call to get the socket descriptor, and, again, for now it's always AF_INET for the socket type, for the socket family.
Type specifies TCP/IP or UDP, those types of things. So that's where -- that, again, may always be TCP/IP. I can't remember the exact constant. I think it's ip proto_tcp or something.
Okay. And then here we're using our make sock addr call to fill in this sock addr struct, and that's a piece, like I said, that you can just sort of reuse. You pass in the port to host saying, I want to connect to this machine on this port; give me the socket addr struct. And once you have that struct, you can then pass it to connect. And there you're saying, connect me to this remote machine on this port as specified at sock addr struct, and locally I want that connection to appear on this socket descriptor -- that's this socket right there -- and that's it.
Once you've done that, then you have the connection, in this case to the server, and then you can use that socket descriptor to start sending and receiving data. So it's pretty simple. It's just getting all your things lined up and done the right way.

Next slide. Okay, now, for the server it's a little different. Here is making the sock addr struct for a server. It starts off fairly similar, but you don't do the gethostbyname, because down here the s addr is not a remote machine; it's going to be a network interface on the local machine.
And n addr any just says, give me any interface. So, you know, if the machine only has one network device, that won't work. And for testing, you might assign that to n addr loopback. Those are two constants that you can set s addr to that are useful, or if you're picking a specific network device, then you can give the address of that local device.
Then this is another silly little thing that you always have to do. I couldn't find anyone to tell me why. Does anyone here know why you have to do this?
FROM THE AUDIENCE: There are two socket instructors. One is (inaudible), one the TCP/IP, and that's (inaudible).
WOODCOCK: Ah. Okay. So, if you don't clear it out, then --
FROM THE AUDIENCE: Actually, I don't think you have to, but it (inaudible).
WOODCOCK: So there may be some legacy systems that if it's not zero, it will think it's the old-style struct or something. Okay. So do that.
So, using that make sock addr server subroutine, here is the server -- here is making a server socket. So, again, you're passing in a port and an address, and the port is the local port, not the remote port. So this is what port do you and the server want to listen for clients on, and the address is what network interface on the local machine do you want the server to listen for clients on.
So when you get call socket, you do it in the identical way that you did for the client, fill in the sock addr struct using the subroutine we saw on the previous slide. And now this is a little different. In order to, you know, as far as the network server is concerned, connect the socket to the address, you have to call bind. And bind just says bind this local socket to this local network interface. And then to actually -- before you can actually begin using the socket, you have to notify the net server that you're ready to listen for clients, and you simply call listen. And you can pass a parameter to listen, which is the number of -- actual number of connections.
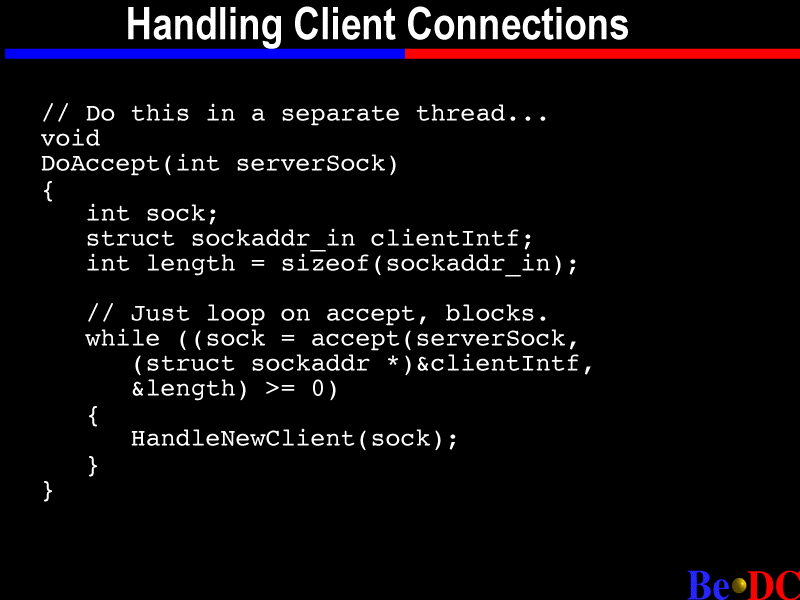
Next slide. Okay. So, this is one place where multithreading comes in kind of handy, accepting client connections; because what you're going to do, once you've got this server socket set up to listen for clients on, after the listen call, then you call accept, and you can see this loop right here. We passed in the server socket descriptor, and we just loop saying accept on the server socket. And you pass in this client interface -- a lot of times you don't really need to use this struct, but you pass it in.
And what you get back here in sock is the socket descriptor of the client. And that's the socket that you use to actually do the communication. The client that you call, bind, listen and accept on is like the entry point for the clients. No actual communication with clients occurs on that socket. And then you loop calling accept. Every time accept returns, if it returns a valid socket descriptor to you, you take that new socket, and you record it somewhere, and you use that socket descriptor for communication with that specific client.
So, a lot of times when you reach this point, this is where you will start spawning threads to handle each socket. So, once again, looping on accept, every time accept returns, it gives us -- if it gives us a valid socket descriptor, then we can handle it in this function.
Actually, I should point out the piece of code that does the accept will often also be in a thread, because most of its time it spends blocked on the accept call. So if you put it in your main program with a bunch of other code, it's not going to be doing much most of the time. It's really going to be screwing up your program.
So -- did we skip a slide?
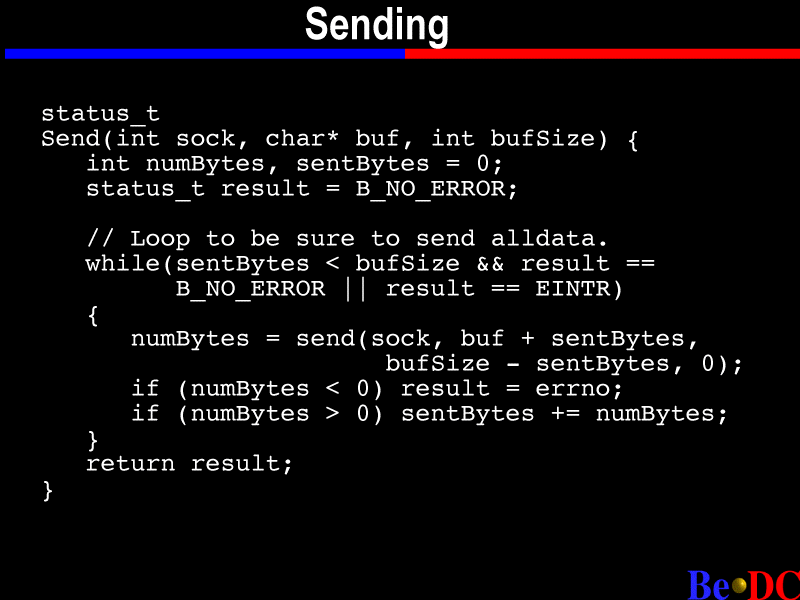
Okay. So, here's sending data, and this is the same for clients or servers. And all we're passing in is a socket descriptor a buffer and a buffer size, and in this case we're passing back at status as to whether or not it worked.
Now, in some cases you might want to rewrite this function to pass back the number of bytes sent, because it is possible, with TCP/IP, to be sending -- you know, you're trying to send 64K of data, and you only send 10K, and the send function will return before it has sent all the data.
Now, in this case, we just handle this -- we have some variables that we set up to keep track of how much data has actually been sent; and it just loops on send until it has all been sent, which might be kind of a brain-dead way to do it, depending on what you're doing, because it may sit there all day and never finish. But anyway...
So, we're looping it until we have sent all the bytes in the buffer. Then we just call send, pass it the socket descriptor and the buffer and the buffer size, and that's about it for send.
Now -- that's receive. You have to worry about the zero log. If you get back number of bytes less than zero, then you've got an error. And some errors are recoverable. One error in particular is EINTER, and that's where, when this loops it says, we haven't sent all the bytes or the result equals EINTER. If the result is anything other than EINTER, then something bad happened, like maybe the client went away or the PPP connection died, or something. But if you get EINTER, it means that the socket has been interrupted. And this is another place where you probably have more issues with this than you would on other systems because of multithreading.
If you're doing two activities on the same socket descriptor at the same time, one of them gets interrupted. So if you're in the middle of receiving data on a socket, and another thread says, oh, I decided to send some data on that same socket, then, boom, the receive returns and gets an error value, EINTER.
We can go to the next slide.
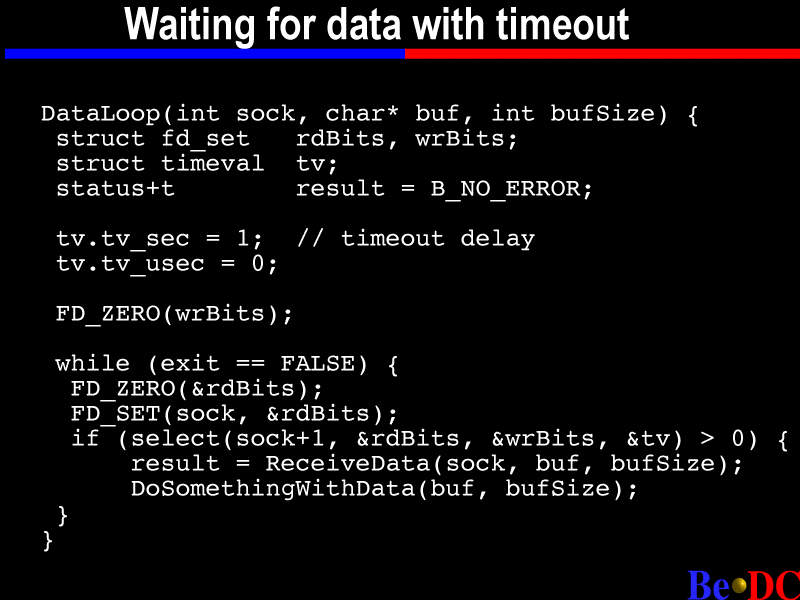
Okay. So, sending is different from receiving, because you always know when you're going to send, you don't really know when you're going to receive. So here's another place where you might want to have a thread. And this is just a loop that's waiting for data to arrive on a socket. Since you don't know exactly when the data is going to arrive, you're going to sit blocked on a function, waiting for the data to come to that socket.
And the way you do this, there are these structures, these FD set structures, and basically you set bits in them to specify which sockets you want to listen for data on. Okay? Don't worry about wrBits for now; just worry about rdBits.
So you can see down here, the first thing we do is zero out the rdBit structure, and then we set the bit for the socket descriptor that we passed in. So in this case we're only listening on one socket.
Now, this is a place where, knowing something about the implementation of the net server, you can get a lot more speed. When you put more than one socket in one of these FD set structures, and then call the select function -- I'm sorry, I should probably talk about select first. When you call select, what select does is, it listens for data to arrive on every socket specified in the rdBits. And then when it returns, the only bits that are set in the rdBit structure are the ones that data actually arrived on. So that's how you can use it to listen for data on more than one socket.
You might set five flags in there for five different sockets, and when it comes back, only one of them may be set, and that's the one that data arrived on. But that's a bad idea with the BeOS, because when you pass a rdBit struct in that has more than one socket set in it, the net server is going to spawn threads, and then when it returns, it is going to destroy all the threads. It does it pretty inefficiently, and it really makes a performance difference.
So one thing you should definitely keep in mind, don't pass in more than one socket. Just select if you can help it.
So, in this case, since we're only listening on one, we can assume that if select returns with no error, that data arrived on that socket. We don't need to actually call the function that checks which socket data arrived on. But that's just another macro called FD is set. So you can say, if FD is set, and then pass in the socket number and the rdBit struct, and it will tell you whether or not data arrived on that socket.
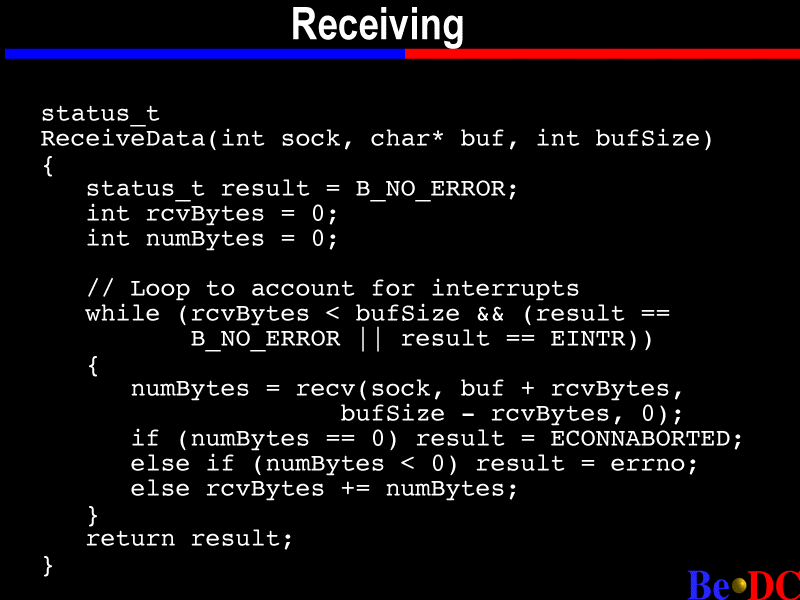
Next slide. Okay. So here's the receive data that we saw inside that data loop function, and -- where are we at here? Okay. So we're passing in a buffer size and a buffer. Now, this is kind of weird, because we're sort of assuming that we know the amount of data that's arriving, which is many times not reasonable, and sometimes you get around that by passing some value up front that says, this is how much data is about to arrive. And in this case, we're just assuming that a certain amount is arriving, for simplicity.
So here again we're doing similar kind of loop bits as we did in send, except instead of calling send, we're calling receive, and it's copying data in. And receive many times will block. And this is what I was talking about earlier, with doing multiple things on the same socket. If you're in the middle of doing a receive and somebody does a send, then receive is going to return a value in num bytes that is smaller than the total size of the buffer, and you're going to get an error value of EINTER.
So, one other important thing about receive, if receive returns exactly zero, that's how you know that the other end went away. That means that the connection has gone away. So you can look all day and not figure that out if nobody tells you.
So that's all the important stuff in receive.

Okay. So, one other thing is, you can -- say, for example, you set something up where you first send four bytes that tells the other side how much data you're going to send. So the other side can call select, and when data arrives, it always knows to look for four bytes. And then it reads those four bytes, and that tells it how much data is in the actual buffer that comes next.
Now, you may do that, and you may call receive before all the data is there, and it's going to block. It's going to sit there and wait until all the data comes, and that's because, by default, sockets are all set up to be blocking. If you call receive and there is no data there yet, it is just going to sit there and wait.
There may be times when you don't want to do that, and there is a socket option to say, set the socket to be nonblocking; in which case, if you call receive and receive would have blocked, it will instead return immediately and set error known to the value E would block. And like I said, block calls only return when they complete or when they get interrupted, or some other error occurs, of course.
Now, we talked earlier about one socket function per socket at a time. So if you have multiple threads going on, you've really got to worry about that.

Okay. So, new to -- I don't know if this was in Advanced Access or not, but it is definitely in Preview -- you can use send signal. Basically you can use all the standard signal functions to interrupt sockets. And there are other places where you have to do this kind of thing, like, for example, you may have some server on, and you've got all these sockets running, all these different threads, and they're all blocked on different things. When you quit the program, they don't go away, because they're blocked.
One simplistic approach is, keep a list of all the thread IDs of all the threads that you spawned to handle all the different sockets, and then you can reasonably assume that they are going to be blocked on whatever, you know, receive or accept or whatever it is they're doing, and you just send them all SIGINTs. Just interrupt them all. And maybe you set a flag to say the program is exiting. So that thread is sitting there looping on select, waiting for data. You interrupt it. It checks a flag that says the program is exiting. So instead of going back into the loop on select or on receive, it instead just exits the thread.
Another way you can do it without using signals is, you can call any network function on the socket, you know. It's probably not a good idea to call send or receive, you know, just for the sake of interrupting the sockets. So what most people normally do is they call get sock name, which returns the socket name, which I think in most cases is useless except for interrupting sockets.

So even though I didn't know it, we have been talking about Berkeley sockets, and that's what Be's TCP/IP implementation is modeled after very closely. And this basically shows the features that are in a standard Berkeley socket implementation that we do have, and we have talked about most of this already, TCP and UDP support and all the standard binding, listening, sending and receiving. We talked briefly about there being a socket option to set nonblocking.
And you can see that here. You call set sock opt on the socket to set socket options. The only two we support are these two, and you can see reuse addr is always on. So it's kind of a no opt. So the only one you really have to play with is blocking or nonblocking. And there are a bunch of others that are in standard Berkeley sockets which we don't have.

Next slide. And there is some other stuff that we don't have. In standard Berkeley sockets, you can treat socket descriptors as file descriptors, which lets you do neat things, like wait for data from a terminal and wait for data from a network connection, and lots of other things. You can close them and control them with standard file type calls, POSIX calls, and you can also pass them to child processes, pass the socket descriptor around to other processes. We can't do those things, although -- I'm speaking for Brad, I'm not sure if I'm saying exactly what he would, but from what I have heard around the office, that stuff is fairly important for the Netscape work that we're doing, so I suspect that that is something that we may have in the future.
And we don't have multicast yet, and like I said earlier, there are some of the lesser known and used socket options that we don't support. And there is something that you can do in select with out-of-band data and exception bits, and if you don't know what that is, don't worry about it. If you do know that, we don't support it yet. Another not very commonly used thing in Berkeley sockets.

So just to sum up what we've been talking about today, you should probably only have one socket in your select call when you're -- in your server when you're waiting for data or you are waiting for data to arrive from clients. You want to handle that by spawning multiple threads and having one thread to handle each socket.
There is one other point about threads and blocking functions that I should probably point out, because I think it's a pitfall that I think a lot of people will make. You are trying to -- when you're trying to make stuff not block, the first thing you might think to do is to use something to keep both threads from happening at the same time. And -- my God, I can't believe this. What is the word for it?
FROM THE AUDIENCE: Semaphore?
WOODCOCK: Semaphore. I just totally blanked. I know it. And you could come up with a situation where you have a semaphore for each socket, right, and each socket has a buffer associated where it gets data from, you know, from somewhere else. That's where incoming data fills in into this buffer. And once the buffer gets called, assuming calls send to that socket again, it's going to, you know -- it's either going to block, or it's going to return E would block, and that's basically what it means; the other side is full. It's like that Far Side cartoon: "May I be excused? My brain is full."
So you can run into a situation when you are using semaphores where you're -- say you've got one semaphore for each socket, right? So both guys decide to send data to each other at the same time. They both grab the semaphore. They both fill up each other's buffers. But since they're holding the semaphore, there is no way for them to do a receive, because the receive is waiting for the semaphore to be released, so you end up deadlocked.
So it's easy to run into stuff like that when you're doing the semaphore stuff with the sockets. So keep that in mind. I think it's kind of good to know a little bit about the way that looks underneath. It helps me to visualize it. You've got that buffer there, and once it fills up, it's going to block, or you're going to get E would block.
So, other things we've done to help you, if you look on the web, we built some C++ objects using networking. There aren't any C++ objects in any of the kits. It's just the low-level Berkeley stuff that you saw today. But this gives you things like a server socket object. And you just tell it, I want to server socket this port on this network device, and, boom, you get it. You don't have to worry about all this ugliness.
And the same thing for client sockets. And we built some stuff on top of that to do messaging over networks, and there are a couple of sample apps that do, like, a shared white board and a check client. Pretty simple stuff, but it will give you somewhere to start, and it works. You won't have to figure out all these nitty-gritties on your own.
This obviously is out of date here. This is from when we did this in the last conference. But I think all the documentation is up to date now for networking, so you've got that available. And I think that's it. So, do we have any questions from the audience?
FROM THE AUDIENCE: When will Be support IPV6?
WOODCOCK: The question was, when will we support IPV6. I don't know exactly. This came up at the last conference, and I don't think Brad gave any clear answer. We think it's important, but he hasn't committed to any date, so that's about the best I can tell you right now.
FROM THE AUDIENCE: This is not really quite a networking question, but since you brought it up, how do you create a thread?
WOODCOCK: Well, we can talk about that, I guess. There is just a function call that you call that creates a thread and gives you a thread ID.
FROM THE AUDIENCE: Does it look like fork, except you get back a thread ID instead of a (inaudible) ID?
WILLIAM ADAMS: Spawn thread. You pass in a function.
WOODCOCK: Right. You pass in a function to spawn thread, and the function always returns a long and always takes a void star.
So you call spawn thread, and that sort of sets everything up. And then you call resume thread, which says, start the thread running, which basically means, start running that function that he specified when you called spawn thread.
So, for example, in this case, you call accept. You get the socket ID. That may be what you pass in as the void star parameter to your handle socket function. So you might say, spawn thread, you know, handle client socket, comma, socket ID, or whatever. I don't remember the exact order of all the parameters. Then you say, resume thread, and then pass in whatever the thread ID was you got back from spawn thread. And now that thread starts running, and it can then look at the void star argument and interpret it as an int, which is a socket descriptor.
FROM THE AUDIENCE: And the thread inherits all the contents, all the file descriptors and everything?
WOODCOCK: The thread does, yes. If it were a separate process, it wouldn't, but the thread does.
FROM THE AUDIENCE: So it's just like in a fork; you need to have some way in your program to keep track of -- if you said -- you don't want to do a read on a socket in two different threads.
WOODCOCK: Right.
FROM THE AUDIENCE: Your program has to keep track of, this socket belongs to that thread; I'm not going to touch it, because it is somebody else's socket.
WOODCOCK: Yes. The question is, how to keep track of all these socket descriptors and which threads are handling them so they don't step on each other. And the simple way is, you just -- once you pass off the socket descriptor to the thread, you just forget about it, and you let the thread handle it. Maybe you keep track of the thread ID, and I guess if you needed to, you could associate the thread ID with the socket ID. But in most of the code I've written, I just, if anything, worry about the thread IDs, and I let the thread sort of manage the socket on its own.
FROM THE AUDIENCE: Where does the spawn thread call fit in the socket, bind, listen, accept, do whatever hierarchy?
WOODCOCK: Okay. Basically the simple way to think of it is, any time you get to one of the networking functions that blocks, you're not going to want to have that in the main part of your program, because it's going to -- once you get a blocking function, it's going to stop until some activity occurs.
Like in the case of accept, accept waits for new client connections. So if you call accept, the program is just going to stop dead in its tracks until a client somewhere out there in the ether decides that it wants to connect to that machine. If that's your main thread that is also running some animation or some game update, whatever, it's going to stop.
So you might get to the point where you do socket, bind, listen, and then you spawn a thread that says, handle client connections. And all that thread does is loop on accept. And every time that thread returns from accept, if it got a valid socket descriptor, maybe it spawns another thread called handle client and passes it to socket descriptor. And then when you're ready to exit the program, you've got to somehow signal all those threads to exit. That's what we were talking about earlier. Maybe you signal the accept thread to exit, and it, since it knows all the other thread IDs, it sends all them signals to kill them, or something like that, whatever scheme you want to come up with.
FROM THE AUDIENCE: But if you are doing something simple like httpd or something that all it does is just sit on the socket and listen, then you could have the accept in the main loop and then spawn after that and it wouldn't be a big deal?
WOODCOCK: So the question is, if you have like a server where its only function is to do network stuff, could you just put accept in the main loop. Yes, I don't see why you couldn't. It's just a question of what else is going on in the program. If all your program is doing is looping on accept and spawning sockets and handling them, then maybe it makes sense to put accept in the main loop of the program.
FROM THE AUDIENCE: Are threads cheap enough that you could, like, do a new thread every time you do a read?
WOODCOCK: Oh, boy. I don't know. What do you think, William? The question is, are threads cheap enough that you could create a new one every time you do a read.
ADAMS: It would probably have more to do with the frequency of the read, not whether you do it on a read or not. So if you're doing reads and it's a thousand a second, that's probably not a good idea. But if you're doing a read once, you know, ten times a second, then maybe you would spawn a thread for that.
WOODCOCK: Or maybe if you want to do something like that, you could have a thread pool. So instead of having to create them each time, you could just pull them out of a pool and reuse them, instead of going through all the time and expense of creating them and destroying them.
Was there a question in the back there?
FROM THE AUDIENCE: I assume you are using Berkeley sockets because the other platforms don't support (inaudible).
WOODCOCK: The question is, we spent a lot of time urging you not to put multiple sockets in select, but if you are porting code, a lot of the code that uses TCP/IP is going to do that. Keep in mind it will work. It's just not optimal. And it's obviously something that we're aware of and that we know is a performance problem. So I can tell you it's something that we should fix and that the networking engineer knows about, but since he's not here, I can't really give you a specific on when it will be fixed.
FROM THE AUDIENCE: Because in most older platforms, all that threading capability, that's the way for them to do it most optimally.
WOODCOCK: Right. I think at the very least, he may change it so it doesn't create them all the time, so it has -- it uses the thread more.
FROM THE AUDIENCE: I think the endianness problem with htons is going to be automatically taken care of between what platform you are on.
WOODCOCK: Right. As long as you have all those calls in the right places when you run your networking code, it should work fine, and you can look at the stuff that we have on the web for exactly where those places are.
I'm sorry. I should have repeated the question. The question was, when you go from platform to platform, is it going to work okay as long as you have all those ntohs and ntohl and all that stuff in the right place. The answer is, theoretically yes. I don't know if you've done any networking testing with what we have already, but -- of course, by the time it's released, I'm sure it will work.
FROM THE AUDIENCE: (Inaudible)
WOODCOCK: The ping of death.
ADAMS: The what?
WOODCOCK: Have you ever heard of that, the ping of death?
ADAMS: No.
WOODCOCK: Do you know any specifics about how that works? I know it's a ping that is done in a certain way that brings down --
FROM THE AUDIENCE: It's a ping that (inaudible).
WOODCOCK: It's just a ping with a really big packet?
FROM THE AUDIENCE: (Inaudible)
WOODCOCK: Oh, really. I think we should try that.
FROM THE AUDIENCE: I tried it on (inaudible).
WOODCOCK: You tried it?
FROM THE AUDIENCE: Yes.
WOODCOCK: Did it kill it?
FROM THE AUDIENCE: No, it didn't. I was doing it to PC users on IOC, and it was working pretty good for me.
WOODCOCK: So apparently we have a little terrorist here who has tried it and says it doesn't seem to affect the BeOS, so we're fortunate there.
FROM THE AUDIENCE: (Inaudible) network drive support.
WOODCOCK: No, but if you look on the web in the last -- at the last Developer Conference, there's a whole section on network drivers. And I don't remember the exact term for it, but there is basically a way to insert something into the flow coming off the network to do things like packet sniffing. Do you remember what they call it, William?
ADAMS: You have a way of getting into the protocol stat, basically. You subclass off of one of our little objects in the network driver, and you are handed the packet, and you would attach or read or do whatever you want to, based on that. So you can get at that if you want.
WOODCOCK: That's not part of this discussion, but it was in another session at the last conference. All of the transcriptions are on the web, so you can go there and read that whole discussion if you want.
The question was about packet sniffing, how can you do something like packet sniffing, which is where you, instead of just seeing the data for a single socket or something, you see all the data that arrives on a network device, even if it is not necessarily for that machine.
Any more questions?
FROM THE AUDIENCE: You put up a summary slide. I didn't quite understand it. There were some things that you could not do on sockets. You were talking about -- no, go forward. You went much too far back. You talked about how sockets and file descriptors were not really equivalent.
WOODCOCK: Right.
FROM THE AUDIENCE: Does that mean you cannot do a read or a write on a socket?
ADAMS: That's right.
FROM THE AUDIENCE: You have to do a send and receive?
WOODCOCK: Yes.
FROM THE AUDIENCE: Is that something that is going to change in the future, because that will probably break a lot of stuff.
WOODCOCK: Well, yes. I mean, it's sort of a big hole. And I don't know when it's going to be fixed, but I'm certain that that is going to be fixed. That's what I was talking about -- the question is about using socket descriptors like file descriptors and doing things like read and write on them, and you can't do that right now, and when will it be fixed.
From what I have heard, it's important for some of the porting that we're doing and some of the porting that our developers want to do. So I think they want to fix that.
ADAMS: That's a fundamental difference in how our networking works versus, say, UNIX, because in UNIX, file descriptors are all handled by the kernel; whereas, in our networking, we have the network server, which is not sitting in the kernel, it's sitting in the user address space.
So they're not file descriptors, because you're actually talking to the server and not the kernel when you are doing all these sends and receives and all that sort of stuff. So, you know, it's not just a bug or fix; it's a fundamental, you know, architectural difference.
FROM THE AUDIENCE: In DR8, using the n addr any sort of thing didn't work quite the way it works in UNIX. Has that been changed?
WOODCOCK: I guess I'm not familiar enough with what the difference was.
FROM THE AUDIENCE: I forget whether the socket call or the line call, but if you use an n addr any, it will bind to the local IP address as opposed to specify what your IP address is. Does that make sense? If I had my code, I could look at it and show you.
WOODCOCK: Maybe we should -- do you have your code here?
FROM THE AUDIENCE: Not on me. If the network connection works, I can show it to you.
WOODCOCK: If you would like, when we're done.
Last question.
FROM THE AUDIENCE: Is there anything you can say about UDP?
WOODCOCK: What exactly do you want to do with UDP?
FROM THE AUDIENCE: Well, I was just wondering, you said -- you mentioned you supported it. Does it work the usual way?
WOODCOCK: Oh, yes. I mean, UPD is a lot simpler, and I don't know exactly what is missing from that, if anything.
The question is about UDP support. I haven't worked with it a lot. All this standard stuff is like, you know...
I guess that was the last one, but did you have a question?
FROM THE AUDIENCE: No. It's just that it's so simple, it's hard to leave anything out.
WOODCOCK: Exactly. I don't think there is anything missing. Do you have a UDP project in mind?
ADAMS: Do you want to share it with the rest of us?
WOODCOCK: There is a little bit of UDP sample code on the FTP site for doing BMessages over the net. So you might want to look at that.
Anything else? I guess that's it. Anyway, Michael told me I have to go. I'll be around if you want to ask me anything. And if you want to check that thing out, we can do that today sometime. I want to watch the 3D stuff, though. (Applause)
(End of session)
Home | About Be | Be Products | BeWare | Purchase | Events | Developers | Be User Groups | Support