

HIROSHI LOCKHEIMER: So this is about Unicode, which of course we use in BeOs. Just in case you don't know what Unicode is, Unicode is an international character encoding standard. I'm sure you've all heard about it already. Microsoft uses it, Apple uses it, NeXT uses it. Rhapsody will probably use Unicode; we don't know obviously, but the next step I'm sure Rhapsody will. So there is definitely -- what I'm going to say here applies to the BeOS but also elsewhere, so it's sort of important, I guess.

Unicode is fixed-width. That means that every character in the coding is always the same size, which is in contrast to multiple byte, multi-byte encoding, such as Shift-JIS in Japanese. It includes characters for the major scripts of the world; that's the point, you have one encoding to describe Japanese, English, whatever.
There are no escape sequences or control codes; that's another good thing. Unicode is always Unicode; it's not modal that you go into Unicode mode and then whatever mode which you find in such encoding, such as JIS. So it's quite easy to deal with that there are no escape sequences.

Codespace. Unicode is 16 bits, I mentioned earlier it was fixed, it's 16 bits as opposed to usually 8 bits for ASCII. So it's double the size. Every character always takes 16 bits, which obviously means that you have more than 65,000 positions for characters. 16 bits, 65,000. 18,000 are still unassigned. That's with the most major scripts of the world, so you probably will not ever run out of space. But if you do, they have this Surrogate Extension Mechanism, which basically says that two Unicode characters mean one glyph. So you basically have one million additional characters if you ever run out of pure Unicode, which I don't know if the Surrogate Extension Mechanism used it. We handle it in the BeOS but probably will never have to actually deal with it.

So in the BeOS we use the Unicode but sort of a transformed Unicode called UTF-8, which stands for UCS Transformation Format, which is a word acronym. I actually don't know what "UCS" stands for; basically, it's just Unicode in 8-bit form. That means -- I'll get to that later. But interestingly enough, the person who decided, at least it was Dominic's idea when he wrote the file system, it was his idea to use UTF-8. Sure enough it was called File System Safe UTF. I guess he was worried at some point he would have to rewrite a lot of stuff to handle pure Unicode.
Now we'll get into why pure Unicode is kind of dangerous and why we use UTF-8 instead. It is a variable length encoding in contrast, which I mentioned is a fixed encoding. I'm saying what we're using is a variable mode of Unicode. Usually all characters in the plain ASCII area, all characters are just one byte that long, which is what everyone has used for ASCII. If you get into copyright characters, "e" with the accent, for example, they're usually two bytes long. Until you get into Kanji, which is Japanese or Korean, for example, you get three bytes per character. So it's a little less efficient than Unicode.
Of course that all depends on what sort of text you're representing. If you have a surrogate pair, that becomes four bytes, 32 bits, which actually is the same as in pure Unicode, because in pure Unicode you have two 16 bits. Here you have two 32 bits, the same for surrogates. But those aren't really used, so I wouldn't worry about it.

So why do we use UTF-8? The major benefit of UTF-8 is it's backwards compatible with 7-bit ASCII. This is a huge win, as Dominic can attest. I'm sure functions such as string copy, string length, they don't work, pure Unicode would not work with those functions, because of the way -- because it's fixed, you can end up with a null character that you didn't really mean it to be a null character. But since you have 00x00 string length, you would think it's a null character, which isn't what you want. In UTF-8 a null character is a null character always. If you encounter a 00x00 in UTF-8, that's always a null character, which is what you want, which this whole parsing for ASCII produces predictable results; that's the whole point of it.
You can use the standard C function, such as string length, string string, string copies, string dupe, all those work. And if you need to know how long the UTF-8 character is, you can look at its first byte and that will tell you how many more bytes should follow, if this UTF character hasn't been munged. So there's sufficient forward parsing for that.
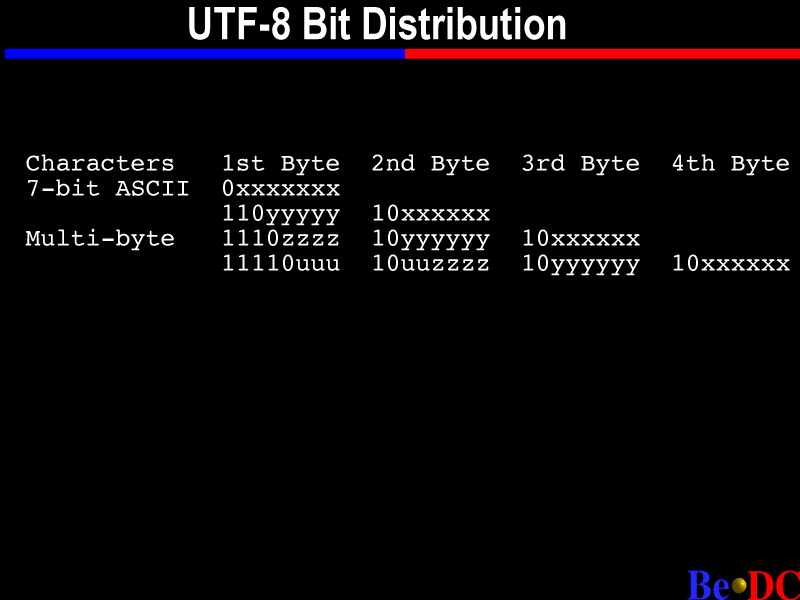
I'll show you the bit distribution; you'll probably never need to do this, but it's interesting. You can tell that the most significant bit, if it's zero, then it's just ASCII. Otherwise you can tell that the number of bytes are in the most significant bit. So if this is a two-byte sequence, you have two 1s and a 0, a three-byte sequence, three 1s and a 0, and so on. So it's pretty straightforward, and it's unambiguous.
Another plus about UTF-8 is that the data types that you use are the standard, the character types, you don't have to use a wide character type or define a uint16 to be a character, you just use what you're used to, which means that less API needed to change. In fact, there was only one function that really had to change because of Unicode, and that was BView: :KeyDown.

Previously in DR8 you used to take a ulong; now it would have been called a uint32. Instead of that we changed it to the pointer, we get the number of bytes, and it tells you how many bytes you've received. Most of the time if you are just typing in English, you'll just get one character and the number of bytes will be one. I'll show you how we use that.

Let's say if you're looking for a tab character in your application, it's pretty at this time straightforward, you don't care how many bytes there are in the arguments, since a tab character in 7-bit ASCII is still the same in UTF-8. So you only care about the first byte in that string, so you reference the first offset there. And you look, you switch for a tab. Otherwise you can get inherited, KeyDown, whatever. Pass.
If you're looking for a more complex character like Hiroshi, which is my name, which is three bytes in Unicode, but who cares, you would have to probably do a string copy, a string compare, or some sort of hand-tuned version of that to check for that, which would involve looking at each byte position. But if you're dealing with plain ASCII, which is 95 percent of the case, unless you're writing a text engine, arrow keys, return, tab, all those, you can just do this. It's pretty straightforward.
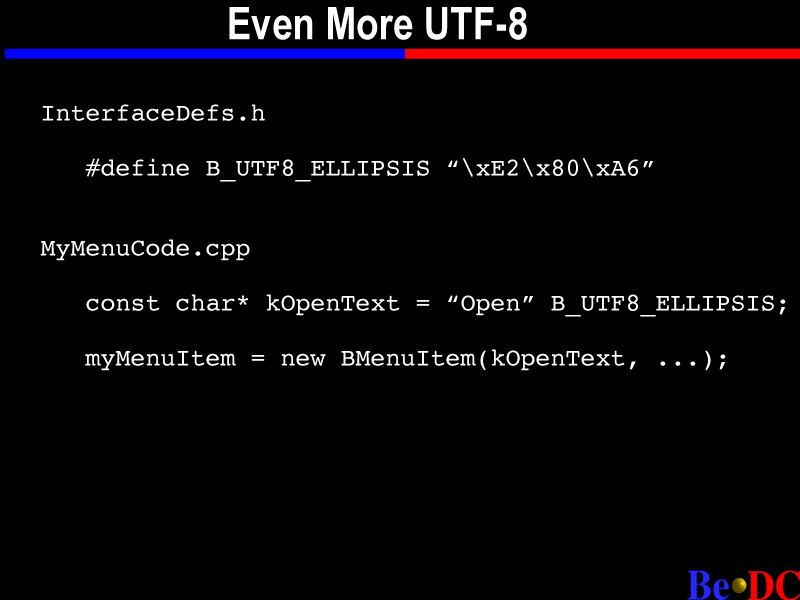
Menu items. Lot of times you want to -- in a menu you have file and then ... That's an ellipsis character, that's three bytes, in UTF-8. Of course if you are using the BeIDE, you can type it, option pair or option, whatever -- I keep on forgetting -- you can type it in, but if you have to maintain this code elsewhere, you won't be able to read it unless you're using an UTF-8-capable editor. You can use one of these predefined defines and interface.
And the way you would use it is the compiler concatenates two strings for you, so you have open and ellipsis characters and you will get the desired result. There are a bunch of characters defined like that in InterfaceDefs. We can't define every interface character. But again, if you're using the UTF-8, you won't have to worry about this.
Talking a little bit about fonts. Pierre is not here right now, he's preparing for the 3D demo he has, but Pierre, our 3D person, did our font engine, and he decided that we're going to handle the Windows-format TrueType fonts, Unicode cmap only. So if you download a Japanese file, you need a Unicode cmap, which Windows NT uses. So you should be able to find these easily.

From a programmer's standpoint, we have
three globally defined objects. BFont is a new
object class in the interface kit, and like
BApplication or BClipboard, we've added three new
globals for those. I'll show you later in the font
panel preferences, I'm sure a lot of you have
already used that, the three settings there and the
preferences that correspond to these three global
fonts.
Now, the reason why we created these global objects is so that people can avoid hard coding font names, which is a pretty good thing to do if you're thinking about internationalizing your font. If you hard code a font name that only has Roman characters in it, then you're never going to be able to display Japanese, because that font doesn't have the data in it. But if you use these objects, there's an abstraction there. So if the user has set a Japanese font with Roman -- usually all Japanese fonts have Roman sections in them, so you will be able to -- I'll show you shortly -- you'll be able to inherit a lot of the international capabilities without really having to do any work yourself.
So these three fonts are pretty important, and I'll show you what I mean. You might notice that this font is a little different from the standard one. This is a Japanese font that I'm using. I'll show you the font panel. These three fonts here, plain, bold and fixed, they correspond; it's user setable. NOWGothic is the font I'm using as the Japanese font. By doing that, StyledEdit uses be_plain_font as its default font setting here. It uses NOWGothic, which is what's set here, the document in Japanese. This style uses BTextViewView, and it's inherited. Even if you don't speak Japanese, for example, you can get this with just using the BTextViewView as if you only use Roman text. As long as you don't hard code a font name, your app will be able to do this.
I'll show you what I mean by that. Another example. FontDemo, for example. I'll copy some text in here. This is the BTextViewControl which uses the BTextView internally. So set that. So font demo, there were no code changes to font demo to be able to do this, because it still uses draw string, it still uses all the Be-supplied widgets. So it's actually pretty easy for this level of internationalization; it's pretty easy, in that you don't have to do anything.
I actually just thought of this five minutes ago. I'll show you how to make a Japanese version of HelloWorld. Let me show you an app. Before I show you HelloWorld, let me show you an app that has been localized. I've shown you internationalization where the one that shifts on the CD can also handle Japanese, for example; that's internationalization. I'll show you localization. From this area we're still working on it, so it's still a demo. But I have this app called Sokyo Tubway, which is a modified version of StyledEdit. So if I open this document in Sokyo Tubway, it works the same way, but the text instead of being in English it's all in Japanese. You can also see dialogues, buttons, anything, all the Be-supplied widgets without really any work to them, except for the text engine, have been internationalized.
Here, in case people are wondering how to input Japanese, I'm sure people have heard of front-end processors, this is something I have going just as a demo. Let's make the font bigger. The type here in Japanese, it will show up here. So that's how, that's an input method here. You type phonetically for the letter. For example, you type HA, you get the Japanese one, and you can convert it to ideographs. And there are many possibilities, obviously. So that's how an input method works. This stuff has not been completed yet, this is still a demo, but this is definitely where we're going.
So now having said that, actually, let's take HelloWorld here. Here we go. Put this in a Clipboard. We'll go back to BeIDE and make sure we can see fonts that are in Japanese.
HelloView. In here since -- I'll show you the English version first. This is the English version; it prints out HelloWorld. Here if I paste in -- instead of this English text, if I paste in what I had typed earlier -- this font is not set correctly -- Courier doesn't have the Japanese font. So, for whatever reason, BeIDE isn't really cooperating, but even if we can't see it, we can compile it. This says hello. Compile it again. And we'll run it. See that it's in Japanese now. Really not much of the code has to change, it's just draw strings. Since draw sting does UTF-8, all those dot-matrix-related functions, all of them use UTF-8. If you just replace the string, you can localize basically.
There are some other cultural issues obviously I won't get into here, but from a purely linguistic standpoint, really little change has to be done to your code.
Also I'll show you, because I'm sort of proud of it, NetPositive. You can see the window title is in Japanese; the text is in Japanese. It's about two days of work in NetPositive. Obviously the Web browser is a little more complex than HelloWorld. As I said, the Web browser is a little more complex than HelloWorld. But that's how it works.
I can also show you Tracker. You can paste the earlier text so you can have the Japanese characters for your file name. I'm sure Dominic can attest, there were no changes to the file system that needed to be done. The same for Tracker, since it all uses draw string. So UTF-8 is all over the system now and really all that had to change was the font engine, and that one function in review. Other than that, we're all UTF-8.
That's about it for my talk. If you have any questions.
FROM THE AUDIENCE: Have you thought yet, as a developer, if I want to allow my app to have separate strings for separate languages; for example, I want it to say "okay" in English, or whatever it is in French or Japanese, where should I store that information?
HIROSHI LOCKHEIMER: Right. Talking something -- if you're a Mac developer?
FROM THE AUDIENCE: Yes.
HIROSHI LOCKHEIMER: Resources, that's a problem that we're having. That HelloWorld, for example, it embeds the string inside the source code, so I have to recompile, which is a problem. We're not really sure how we're going to do this yet. It's not that difficult of a problem, it's just what's the most elegant way of doing it. I'm not sure if you're familiar with the archiving stuff, I think Peter has a talk about it tomorrow.
Replicants. Part of that is archiving a view. Of course we can just archive it and save it to disk, and you could lay out a view; for example, a string view that has a string. It can have a English one, a Japanese one. What we have to come up with is the file format for that. It's where we're going to put that data, a resident issue.
FROM THE AUDIENCE: You're having sizing issues too?
HIROSHI LOCKHEIMER: Not only for strings but also for layouts, which is a problem for German. I've heard German text is a lot longer, so you want to change not only the string but the layout. So I think we're going to go in the direction of Replicants, not in the sense of objects but just archiving, saving objects to disk.
Any other questions?
FROM THE AUDIENCE: In the Tracker window there I'm assuming you're using strict unit code as the sort order. Internationalization, anybody who has done any work there knows even different languages that use the same scripts have different sort orders. Can you speak a little bit to that.
HIROSHI LOCKHEIMER: Right. The sorting issue is a very difficult one. You're right, what Tracker does is just numerical value basically of the bytes, which actually the Unicode Codespace has been organized in one, per language it's been designed so that there is some order to it. Of course, for example, it's usually not the order you want for Japanese. For English obviously it's in alphabetical order, but for Japanese it's usually not what you want, and as you mentioned, there are three or four ways of doing it per language.
So that's a very difficult issue, it probably involves a lot of mapping tables and all that. We didn't really get to that, I'm not sure how we're going to get around that, but that's definitely -- we'll probably need a string compare, a Unicode string compare or whatever function that handles that.
FROM THE AUDIENCE: It might be worth pointing out that computers built in America by native English speakers don't do sort order correctly either. If you look at alphabetized titles and stuff, you'll have numbers beginning, when they should be by spelling, by the number, things like that. Look at the way ASCII orders it, it comes up wrong there too.
HIROSHI LOCKHEIMER: It's difficult to define what's right. There's also the preference issue there too; I think some people might want numbers first. It's really difficult. So obviously it has to be settled by the user to some extent. But right now there is no mechanism for the user to set it or even for the programmer to get that data from the system, at least they didn't write it.
FROM THE AUDIENCE: I was wondering if you ship a font with a full character set?
HIROSHI LOCKHEIMER: We don't. There is a font called Cyberbit by Bitstream, Bitstream.com, and their Cyberbit font is pretty comprehensive. I think it misses some scripts, but it's free for downloads. The problem with that font is -- I was just talking to someone earlier about this -- the Japanese, Korean portion is not hinted at all, which means that our TrueType renderer expects hinted fonts, so it gets a pretty -- I can show you -- it can get a pretty nasty effect. At bigger point sizes it's not that big of a problem.
So here is Cyberbit. You can see here that it's grayed out. That's because it's not hinted. There has been some talk mentioning this might be a problem with the anti-aliasing that we do. It's really not the anti-aliasing; it's really just the way this font is in that it's incomplete. But if you want to just play around, it's a good font.
Any other questions?
FROM THE AUDIENCE: You have some finished right justified?
HIROSHI LOCKHEIMER: Solution or write justified, right. Currently our file engine does not do right to left. You would have to ask Pierre whether he has any plans in the near future for that, but I'm sure if there's enough demand, we'll do that. So since our font engine doesn't have it, obviously TextView can't do it, so right now there is no solution for that. In BFont, in the BFont object that I was mentioning earlier, there was a function to get the direction of the font but unimplemented.
Questions? I don't see any questions. So if you have any more questions, I'll be around, feel free to come up to me. Thanks.
(Applause)
Home | About Be | Be Products | BeWare | Purchase | Events | Developers | Be User Groups | Support